












Cloaking
Accueil > Agence SEO > Encyclopédie SEO > Cloaking
Définition
Le cloaking, ou dissimulation, est une méthode controversée d’optimisation pour les moteurs de recherche. Elle consiste à montrer des contenus différents aux moteurs de recherche et aux utilisateurs. Classée parmi les techniques de « Black Hat SEO » pour son manque d’éthique, cette stratégie enfreint les directives établies par des moteurs de recherche tels que Google, Yahoo et Bing.
Cette pratique vise principalement à tromper les algorithmes des moteurs de recherche afin d’améliorer artificiellement le classement d’un site dans les résultats de recherche, tout en présentant une version différente du contenu aux visiteurs du site. Le cloaking peut induire en erreur les utilisateurs en les dirigeant vers du contenu qu’ils n’attendaient pas, compromettant ainsi la qualité et la pertinence des résultats de recherche.
Il est crucial pour les professionnels du SEO et les propriétaires de sites web de comprendre que le recours au cloaking expose à des risques significatifs, notamment des pénalités sévères de la part des moteurs de recherche, pouvant aller jusqu’à l’exclusion complète du site des résultats de recherche.

Le cloaking schématisé
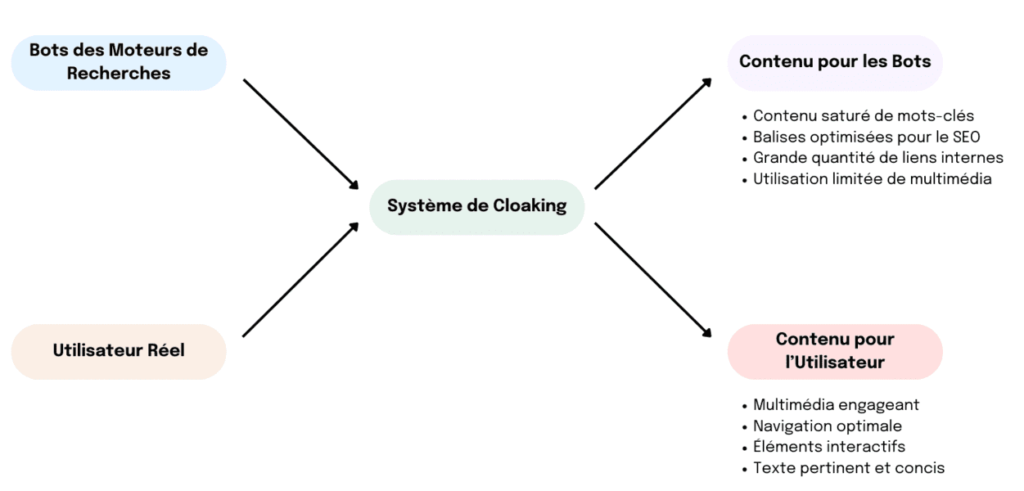
Différentes techniques de Cloaking
Il existe une grande variété de techniques de cloaking. Chacune d’entre elles est plus ou moins compliquée.
Cloaking à partir de l'user agent
Lorsqu’un utilisateur ou un robot d’exploration des moteurs de recherche visite un site web, le navigateur utilisé renvoie une série d’informations, indiquant au serveur qui a visité le site. Il peut s’agir d’un humain ou d’un robot du moteur de recherche, qui explore votre page.
La technique de cloaking basée sur l’User Agent se concentre donc sur l’identification du type de visiteur (humain ou robot) à travers la chaîne de caractères “User Agent” transmise par le navigateur dans chaque requête HTTP.
Le cloaking sur l’user agent se divise donc en 2 étapes :
- Détection de l’User Agent : Lorsqu’une requête est reçue, le serveur examine l’User Agent pour déterminer si la demande provient d’un robot d’indexation (par exemple, GoogleBot) ou d’un utilisateur réel.
- Sélection du contenu : Si la requête est identifiée comme provenant d’un robot d’indexation, le serveur renvoie vers une page optimisée pour le SEO. Si la requête provient d’un humain, le serveur présente le contenu réel du site, optimisé pour l’expérience utilisateur.
Voici un exemple pour vous aider à comprendre à quoi ressemblent les chaînes User Agent d’un robot d’indexation Google (Googlebot) et d’un utilisateur réel (dans cet exemple, Google Chrome sur Windows 10).
- User Agent de Googlebot : Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
- User Agent d’un utilisateur réel (Google Chrome sur Windows 10) : Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36
Cloaking sur l’adresse IP
Le cloaking, se basant sur l’adresse IP, suit la même logique que la technique précédente, qui, elle, se basait sur le user-agent. À partir de cette technique, on cherche à détecter les classes d’IP utilisées par les robots de Google, afin d’afficher un contenu différent lorsqu’il s’agit d’un utilisateur réel ou bien d’un robot Google.
Attention, la liste d’IP fournie précédemment n’est pas exhaustive et ne contient pas toutes les IP, qui d’ailleurs changent de temps à autre.
Exemples de cloaking
Rien ne vaut un exemple concret pour comprendre le concept de cloaking. Google nous donne d’ailleurs deux exemples dans son article dédié au cloaking. Voici deux exemples de cloaking selon Google :
- “Affichage d’une page sur des destinations de voyage pour les moteurs de recherche et d’une autre sur des médicaments à prix réduit pour les utilisateurs. »
- « Insertion de texte ou de mots clés dans une page uniquement quand le user-agent qui demande la page est un moteur de recherche, et non un visiteur”
Si vous voulez un exemple concret, nous pouvons vous citer le cas très connu de BMW. Le cas de BMW en 2006 est un exemple notable de l’utilisation de techniques de cloaking, ce qui a conduit à la suppression de leur site de l’index de Google.
BMW avait mis en place un système de redirection JavaScript qui présentait aux moteurs de recherche un contenu différent de celui vu par les utilisateurs réels, dans le but de manipuler les résultats de recherche pour un meilleur classement.
Cette pratique a été découverte par Google, qui a jugé qu’elle violait ses directives pour les webmasters, en particulier la règle qui stipule de ne pas tromper vos utilisateurs ni présenter un contenu différent aux moteurs de recherche que celui affiché aux utilisateurs.
En conséquence, le site de BMW a été complètement retiré de l’index de Google, ce qui a rendu le site pratiquement invisible sur le moteur de recherche pendant un certain temps, jusqu’à ce que le problème soit résolu et que le site soit réintégré. Si vous souhaitez plus d’informations sur le cas de BMW, nous vous recommandons cet article « Google Bans BMW for Search Spamming« , écrit par Loren Baker, fondateur du « Search Engine Journal ».
Différence entre Cloaking et Obfuscation de liens
Si vous débutez en SEO, vous allez probablement rencontrer le terme d’obfuscation de liens, souvent confondu avec le cloaking. Bien qu’il s’agisse de deux techniques de dissimulation, elles poursuivent des objectifs différents.
L’obfuscation de liens a pour principal objectif de dissimuler la présence de liens aux moteurs de recherche. Cette technique est utilisée par les webmasters et les professionnels du SEO pour optimiser le budget de crawl.
Le cloaking, quant à lui, implique de montrer une version de page différente en fonction de si le visiteur est un robot d’indexation de Google ou un utilisateur réel.
En résumé, l’obfuscation de liens vise à cacher des liens aux moteurs de recherche dans le but d’optimiser le budget de crawl, tandis que le cloaking cherche à montrer un contenu différent à Google et aux utilisateurs, souvent pour des raisons considérées comme non éthiques.
Impact du cloaking sur le référencement
L’utilisation de techniques de cloaking peut améliorer votre classement à court terme sur les SERP. Malheureusement, cela ne sera que de courte durée. Une fois la supercherie découverte par les robots des moteurs de recherche, votre site risque de subir une pénalité de Google. Dans le meilleur des cas, cela se traduira par une perte de position dans les classements ou bien par la désindexation totale de votre site.

Risques du Cloaking : Que dit Google ?
Le cloaking, lorsqu’il est utilisé de manière non éthique (Black Hat), peut s’avérer risqué, car il est considéré comme du spam par Google. Selon un article de Google regroupant les « Règles concernant le spam dans la recherche sur le Web Google » :
« Nous détectons les contenus et comportements qui enfreignent les règles, à la fois à l’aide de systèmes automatisés et, si nécessaire, d’une révision humaine pouvant aboutir à une action manuelle. Les sites qui ne respectent pas nos règles peuvent être moins bien classés dans les résultats ou ne pas y figurer du tout. »
Les risques sont clairs. Si vous êtes pris en flagrant délit, Google pourrait bien vous faire perdre des positions dans les classements des résultats de recherche, et dans le pire des cas, l’élimination et la désindexation de votre site.
Comment Google détecte les techniques de cloaking ?
Google dispose de plusieurs moyens les aidant à détecter les sites utilisant des techniques de cloaking.
- Service de dénonciation : Google a mis en place un service de dénonciation, destiné aux webmasters. Ce service permet aux utilisateurs de dénoncer un site qui ne respecte pas les règles de Google concernant le spam. Nous n’avons pas d’information claire sur la manière dont Google traite ces demandes, mais ce qui est sûr, c’est qu’ils utilisent ces rapports pour perfectionner leur système de détection de spam.
- Système automatisé : Google crawl constamment le web à l’aide de ses robots. Cela leur permet entre autres de détecter de possibles infractions de leurs règlements concernant le spam. Il est d’ailleurs connu que Google a mis en place des robots masqués, permettant de crawler le web tout en se faisant passer pour des utilisateurs humains.
Il est important de relever qu’une action manuelle, de la part de Google, peut être employée afin de vérifier le respect des règles concernant le spam, par la page web mise en cause.
Les définitions les plus populaires
accessibilité web
algorithme google
crawler
google EAT
google search console
budget crawl
pagerank google
recherche vocale
keyword stuffing
google penguin
filtre google
moteur de recherche
Boostez votre visibilité
N’hésitez pas à nous contacter pour obtenir un devis gratuit et personnalisé.
Notez ce page