















Configurazione di Screaming Frog
La corretta configurazione dello strumento sarà molto importante per poter analizzare un sito in profondità e ottenere tutti i dati necessari. Scopri passo dopo passo come configurarlo per ottenere risultati ottimali.
Lanciare il tuo primo crawl su Screaming frog :
Quando apri lo strumento, la prima cosa che vedrai è una barra in cui puoi inserire l’URL del sito che desideri analizzare:

È sufficiente inserire l’url e selezionare start per avviare il primo crawl. Una volta avviato, se si desidera interromperlo, è sufficiente fare clic su Pausa e poi su Clear per riportare a 0 il crawl.
Configurare il tuo Screaming Frog SEO Spider :
Ci sono molti modi per configurare il crawler in modo che restituisca solo le informazioni che interessano davvero. Questo può essere molto utile, ad esempio, quando si effettua il crawling di siti con molte pagine o si vuole semplicemente analizzare un sottodominio.
Per farlo, basta andare nel menu in alto e selezionare
Configuration
1/ Spider
CRAWL
Spider è la prima opzione disponibile quando si accede al menu di configurazione. È qui che si può decidere quali risorse si desidera sottoporre al crawling.
In genere si dovrebbe avere una finestra con questo aspetto:
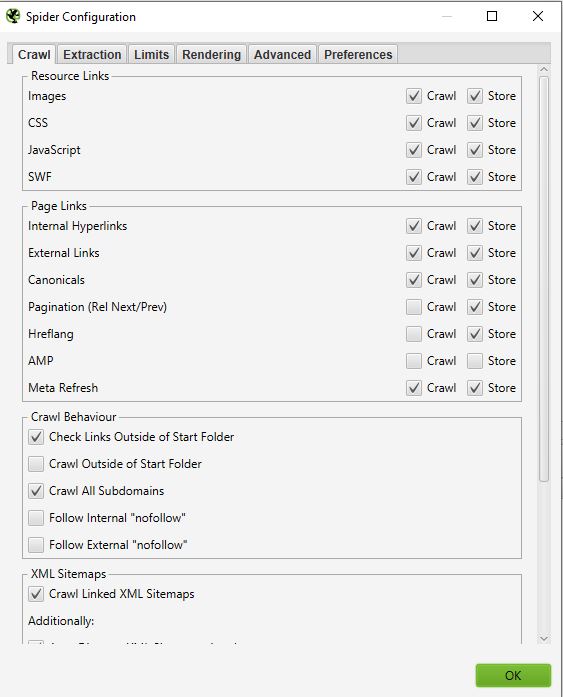
- Link alle risorse :
È possibile, ad esempio, decidere di non effettuare il crawling delle immagini del sito; Screaming frog escluderà quindi dal crawling tutti gli elementi img: (img src=”image.jpg”). Il crawl sarà più veloce, ma non sarà possibile analizzare il peso delle immagini, gli attributi delle immagini…
Sta a te scegliere cosa analizzare da questo punto di vista.
Buono a sapersi: può succedere che alcune immagini vengano visualizzate se sono sotto forma di href e non hanno un img src.
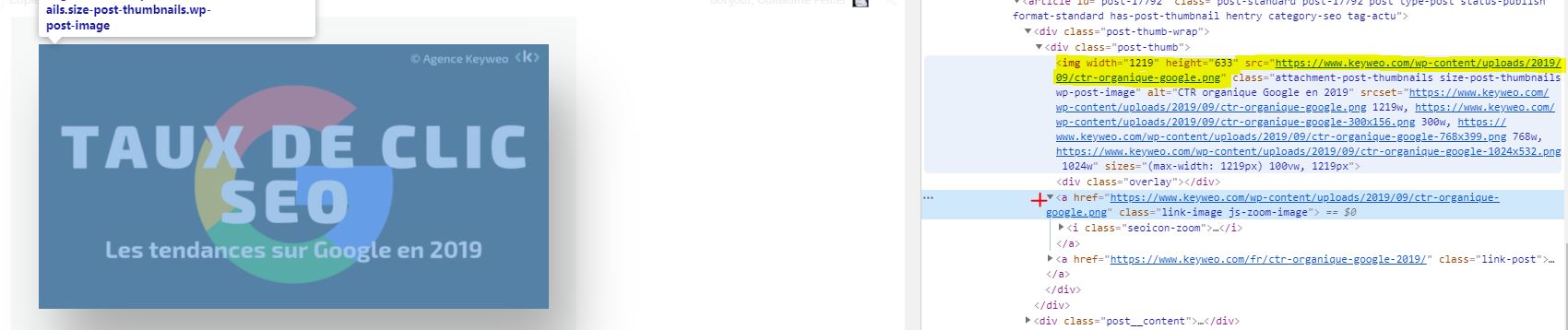
Nella schermata qui sopra, ciò che è in giallo non verrà crawlato, mentre il link a fianco della croce rossa verrà comunque crawlato.
Nella maggior parte dei crawl si avrà una configurazione di base in questa finestra. Si consiglia di controllare il crawl e la memorizzazione di immagini, css, javascript e file SWF per un’analisi approfondita.
- Collegamenti alla pagina :
In questa parte si può anche decidere che cosa si vuole crawlare in termini di link. Ad esempio, si può dire che non si vuole effettuare il crawling di canonicals o di link esterni. Anche in questo caso, spetta a te scegliere cosa analizzare.
Esempio :
Crawl con collegamenti esterni e senza collegamenti esterni
Crawl con link esterni :
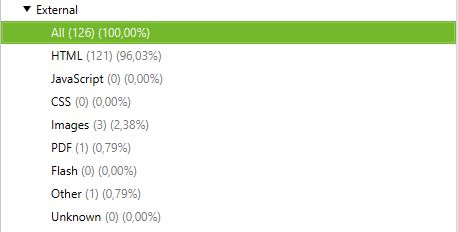
Crawl senza link esterni :
- Crawl Behaviour
In questa parte è possibile dare istruzioni allo strumento per eseguire il crawling di pagine specifiche del sito.
Esempio :
Hai delle pagine in sottodomini e vuoi comunque effettuare il crawling per analizzarle? Selezionando Crawl All subdomains, se sul tuo sito è presente un link a queste pagine, Screaming Frog sarà in grado di rilevarle nel suo crawler.
Di seguito si può vedere un sito con sottodominio: blog.domainname. Selezionando crawl all subdomains prima di lanciare il crawl, l’applicazione visualizza anche tutte le url di questo sottodominio.

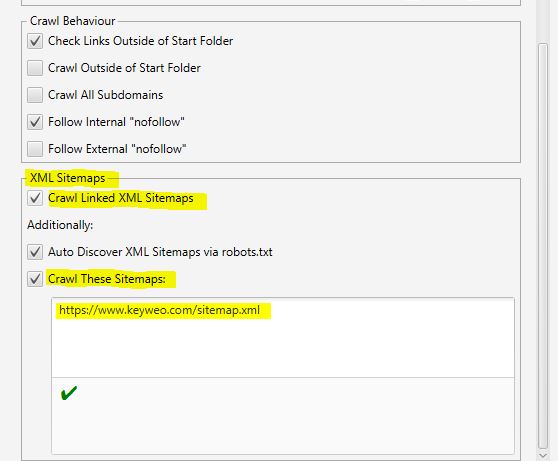
- XML Sitemaps
Hai una Sitemap sul tuo sito? Allora potrebbe essere interessante analizzare le discrepanze tra ciò che hai nella tua Sitemap e le URL che Screaming Frog trova.
Qui è possibile indicare a Screaming Frog dove si trova la tua Sitemap, in modo che possa analizzarla.
Per farlo è sufficiente :
1- Controllare le sitemap XML collegate al crawl
2- Controllare le sitemap di Crawl
3- Compilare l’url della sitemap
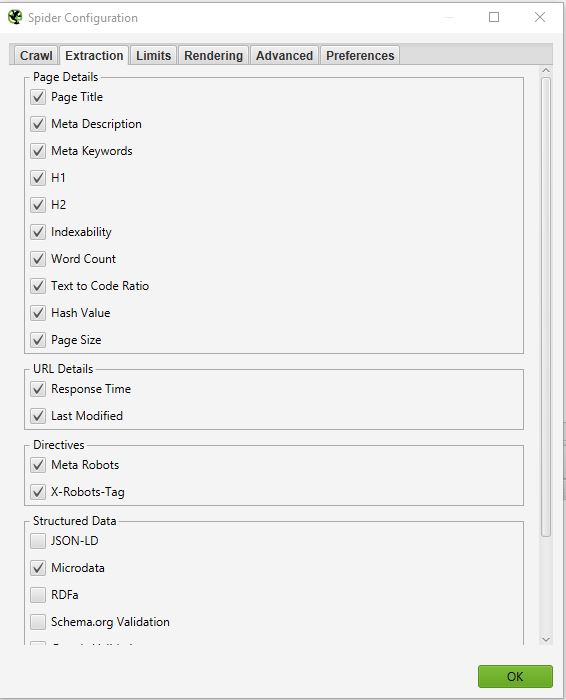
EXTRACTION
In questa sezione è possibile scegliere i dati che Screaming Frog deve estrarre dal sito e visualizzare nella sua interfaccia.
Esempio :
Se si deseleziona la voce Word Count (Conteggio parole), non si avrà più il conteggio delle parole di ogni pagina caricata.
Normalmente non si dovrebbe modificare troppo questa parte, poiché di solito le informazioni estratte dal sito, che vengono selezionate per impostazione predefinita, sono quelle principali.
Una cosa che potrebbe essere interessante, se si vuole fare un audit SEO approfondito, è selezionare le informazioni relative ai dati strutturati: JSON-LD, Microdata, RDFa, Schema.org Validation.
Questo ti fornirà informazioni preziose sull’implementazione dei microdati nel tuo sito, come ad esempio: le pagine che non hanno microdati, gli errori associati, i tipi di microdati per pagina.
LIMITS
In questa terza scheda è possibile impostare dei limiti per il crawler. Questo può essere particolarmente utile quando si vogliono analizzare siti con molte pagine.
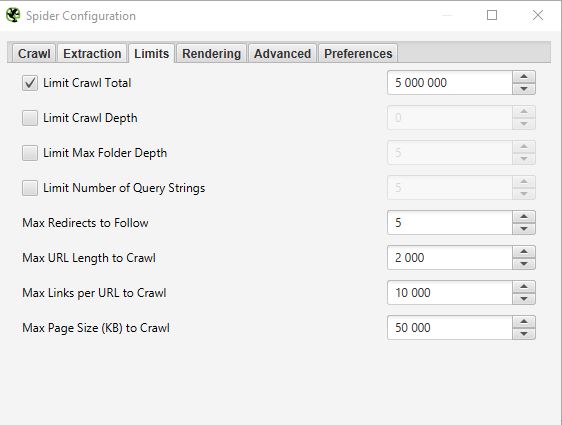
- Limit Crawl total :
Questo è il numero di URL che Screaming Frog è in grado di esaminare. In generale, quando analizziamo un sito, non ha senso limitare il numero di URLs. Ecco perché di solito non tocchiamo questo parametro.
- Limit Crawl Depth :
È la profondità massima a cui si vuole che il crawler acceda. Il livello 1 è costituito dalle pagine situate a un clic di distanza dalla homepage e così via. Non modifichiamo quasi mai questo parametro perché è interessante osservare la profondità massima di un sito in un audit SEO. Se è troppo profondo, dovremo intervenire per ridurre la profondità.
- Limit Max Folder Depth :
In questo caso, si tratta della profondità massima della cartella alla quale si vuole che il crawler abbia accesso.
- Limit number query string :
Alcuni siti possono avere parametri del tipo ?x=… nei loro url. Questa opzione consente di limitare il crawl alle URL contenenti un certo numero di parametri.
Esempio : Questa URL https://www.popcarte.com/cartes-flash/carte-invitation/invitation-anniversaire-journal.html?age=50&format=4 contiene due parametri age= e format=.
Potrebbe essere interessante limitare la scansione a un singolo parametro per evitare di scansionare decine di migliaia di URL.
Questa opzione è molto utile anche per i siti di e-commerce con molte pagine e inserzioni con collegamenti incrociati.
- Max redirect to Follow :
Questa opzione consente di definire il numero di reindirizzamenti che si desidera far seguire al crawler.
- Max URL Length to Crawl :
Modificando questo campo, è possibile selezionare la lunghezza delle URL che si desidera sottoporre al crawling. Non lo usiamo quasi mai, se non in casi molto specifici.
- Max links per URL to Crawl :
Qui è possibile controllare il numero di link per url che Screaming Frog deve analizzare.
- Max page Size to Crawl :
Qui è possibile scegliere il peso massimo delle pagine che il crawler sarà in grado di analizzare.
RENDERING
Questa finestra è particolarmente utile se si desidera eseguire il crawling di un sito che utilizza un framework javascript come Angular, React, ecc.
Se stai analizzando un sito di questo tipo, puoi configurare il tuo crawler in questo modo:
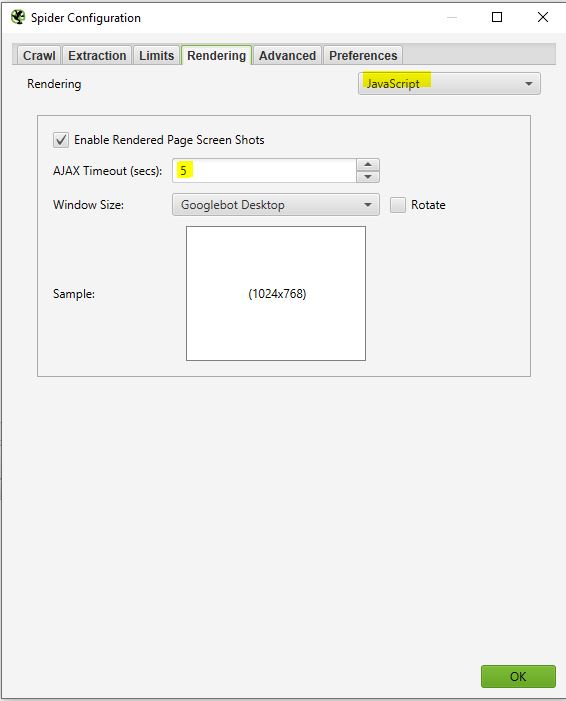
Screaming frog scatterà degli screenshots delle pagine analizzate, che potrai poi trovare nei risultati del crawl facendo clic sulle URL che vengono visualizzate e selezionando la pagina renderizzata.
Se noti che la tua pagina non viene resa in modo ottimale in quest’area, guarda le risorse bloccate nel riquadro di sinistra e puoi provare a modificare il TIMEOUT AJAX.
ADVANCED
Arrivati a questo punto, si ha già una buona configurazione del proprio crawler. Tuttavia, se si vuole andare oltre, è possibile gestire alcuni parametri in questa sezione “Advanced”.
Ecco alcune impostazioni che potrebbero essere utili:
- Pause on High memory usage :
Questa opzione è pre-selezionata per impostazione predefinita nel pannello di controllo di Screaming Frog. Sarà molto utile e potrà essere attivata quando si effettua il crawling di siti di grandi dimensioni. Infatti Screaming frog quando arriva al limite della sua memoria sarà in grado di mettere in pausa il processo di crawl e di avvisare l’utente in modo che possa salvare il progetto e continuarlo se lo desidera.
- Always follow redirect :
Questa opzione è utile nel caso in cui siano presenti stringhe di reindirizzamento sul sito che si sta analizzando.
- Respect noindex, canonical et next-prev:
In questo caso, il crawler non mostrerà nei risultati del crawling le pagine che contengono questi tag. Anche questo può essere interessante se si analizza un sito con molte pagine.
- Extract images from img srcset attribute :
In questo caso, il crawler estrarrà le immagini con questo attributo. Questo attributo è utilizzato soprattutto in caso di gestione reattiva di un sito. Sta a te valutare se è pertinente recuperare queste immagini.
- Response Timeout (secs) :
È il tempo massimo che il crawler deve attendere per il caricamento di una pagina del sito. Se questo tempo viene superato, Screaming Frog può restituire un codice 0 che corrisponde a un “timeout della connessione”.
- 5xx response retries :
Questo è il numero di volte che Screaming Frog deve ricontrollare una pagina in caso di errore 500.
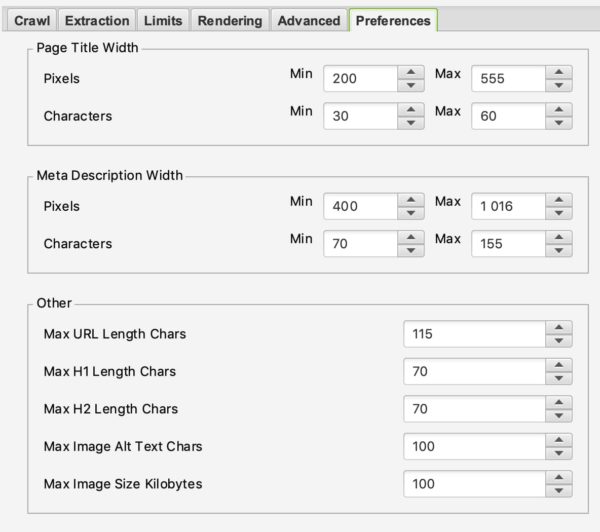
PREFERENCES
In questa parte sarà possibile definire realmente cosa Screaming Frog deve segnalare in caso di errore.
Ad esempio, è possibile definire il peso massimo delle immagini che può essere considerato un problema o la dimensione massima di una meta descrizione o di un titolo.
Sta a te definire le tue regole SEO in base alla tua esperienza e ai tuoi desideri.
2/ Robots.txt
Complimenti per l’impegno impiegato per arrivare a questo punto. La prima parte non è ovvia, ma è fondamentale per una buona configurazione del crawler. Questa parte sarà molto più semplice della precedente.
Selezionando Robots.txt dal menu è possibile configurare il modo in cui Screaming Frog deve interagire con il file robots.
SETTINGS :
Normalmente si dovrebbe vedere questo quando si arriva alla sezione delle impostazioni dei robot
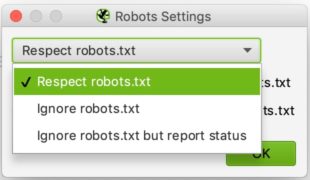
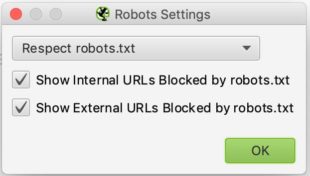
La configurazione è relativamente semplice. Nell’elenco a discesa è possibile indicare a Screaming Frog se deve rispettare o meno le indicazioni del file robots.txt.
Il caso ignore robots.txt può essere utile, ad esempio, se il sito che si desidera analizzare non consente a Streaming Frog di effettuare il crawling per qualche motivo. Selezionando ignora robots.txt, Screaming Frog non lo interpreterà e sarà possibile effettuare normalmente il crawling del sito in questione.
Il caso del rispetto di robots.txt è quello più ricorrente e si può quindi dire, tramite le due caselle di controllo sottostanti, se si vuole vedere nei report le URL bloccate da robots.txt, siano esse interne o esterne.
CUSTOM :
In questo pannello di controllo è possibile simulare il proprio robots.txt. Questo può essere particolarmente utile se si vogliono testare le modifiche e vederne l’impatto durante un crawl.
Si noti che questi test non influiscono sul file robots.txt online. Se si desidera modificarlo, lo si dovrà fare da soli dopo aver effettuato i test in Screaming Frog, ad esempio.
Ecco un esempio di test:
Abbiamo aggiunto una riga per impedire il crawling di qualsiasi url contenente /blog/
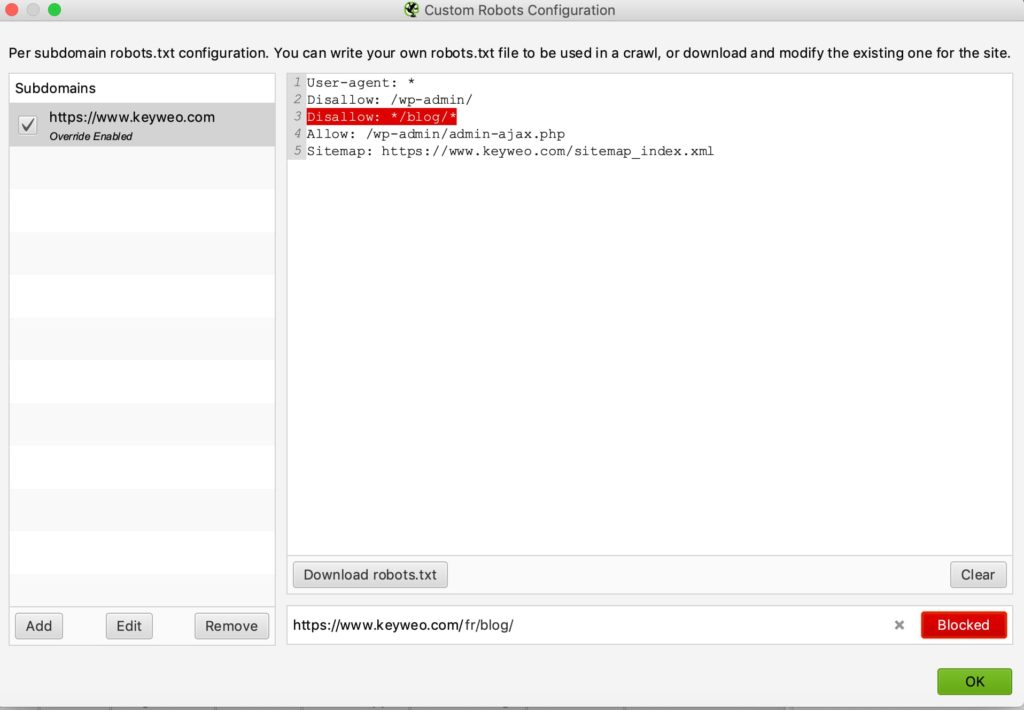
Se guardi qui sotto vedrai che nel test che abbiamo effettuato con keyweo.com/en/blog l’URL è stata effettivamente bloccata.
3/ URL Rewriting
Questa funzione è molto utile nel caso in cui le URL contengano parametri. Nel caso, ad esempio, di un sito di e-commerce con un elenco di filtri. In questa parte sarà possibile chiedere a Screaming Frog di riscrivere le URL nel mentre.
REMOVE PARAMETERS
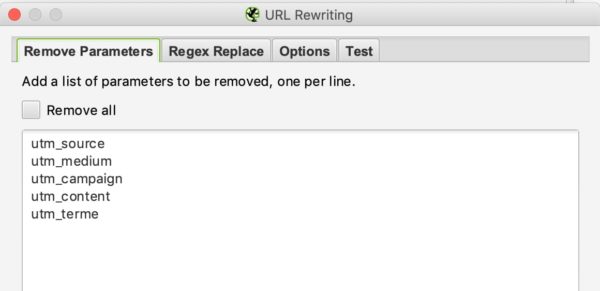
In questa sezione è possibile indicare al crawler di rimuovere alcuni parametri per ignorarli. Questo potrebbe essere particolarmente utile per i siti con UTMs nelle loro URLs.
Esempio:
Se vogliamo rimuovere i parametri utm nelle nostre URL, possiamo inserire questa configurazione:
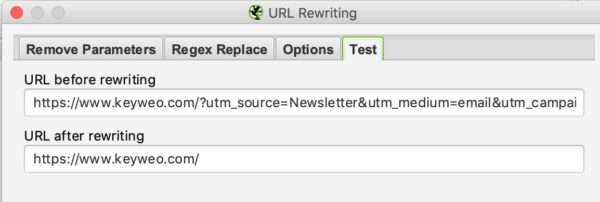
Poi, per verificare se funziona, basta andare nella scheda Test e inserire un URL contenente questi parametri per vedere cosa restituisce:
REGEX REPLACE
In questa scheda è possibile sostituire rapidamente i parametri con altri. Si possono trovare molti esempi nella documentazione di Screaming Frog qui
4/ Include e Exclude
In Keyweo utilizziamo spesso queste funzioni. È particolarmente utile per i siti con molte URLs, se si desidera eseguire il crawling solo di alcune parti del sito. Screaming Frog sarà in grado di visualizzare solo determinate pagine nell’elenco dei risultati del crawling tramite le indicazioni fornite dall’utente in queste finestre.
Se gestite o analizzate siti di grandi dimensioni, questa funzionalità sarà molto importante da padroneggiare per risparmiare molte ore di crawling.
L’interfaccia di inclusione ed esclusione si presenta come segue:
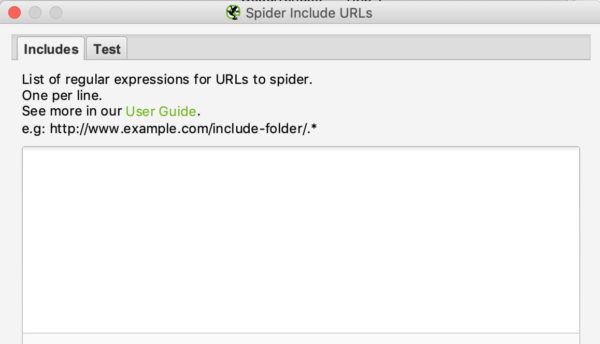
È possibile elencare le URLs o gli schemi di URL da includere o escludere nella casella bianca, inserendo una URL per riga.
Ad esempio, se desidero eseguire il crawling solo delle urls /fr/ su Keyweo, ecco cosa posso inserire nella finestra include:
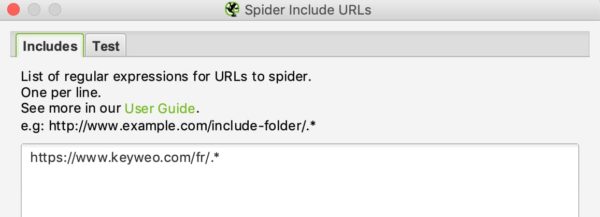
Come per la riscrittura delle URLs, è possibile verificare se l’inclusione funziona testando una URL che non dovrebbe essere inclusa nel crawling:
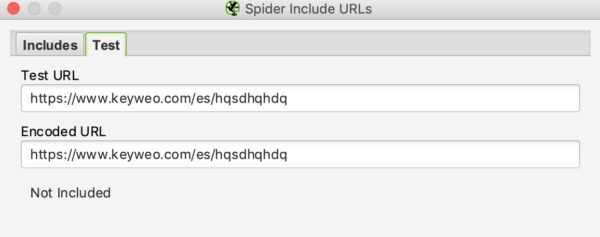
Nell’esempio precedente si può notare che l’include funziona, poiché le URLs contenenti /es/ non vengono prese in considerazione.
Se si desidera escludere determinate URL, la procedura è simile.
5/ Speed
In questa parte si può scegliere la velocità con cui si desidera che Screaming Frog effettui il crawling del sito da analizzare. Questo può essere utile quando si desidera eseguire la scansione di siti di grandi dimensioni. Lasciare l’impostazione predefinita potrebbe richiedere molto tempo per effettuare il crawling del sito web. Aumentando l’impostazione Max Threads, Screaming Frog potrà eseguire il crawling del sito molto più velocemente.
Questa impostazione deve essere usata con cautela, poiché può aumentare il numero di richieste HTTP fatte a un sito, rallentandolo. In casi estremi, può anche causare il blocco del server o il blocco del server stesso.
In generale, si consiglia di lasciare questa impostazione tra 2 e 5 Max Threads.
Si noti anche che è possibile definire un numero di URL da scansionare al secondo.
Non esitare a contattare i team tecnici che gestiscono il sito per gestire il crawl del sito ed evitare un sovraccarico.
6/ User agent configuration
In questa parte si può definire con quale user agent si vuole effettuare il crawling del sito web. Per impostazione predefinita sarà Screaming Frog, ma è possibile, ad esempio, eseguire il crawling del sito come Google Bot (Desktop) o Bing Bot.
Questo può essere utile, ad esempio, nel caso in cui non sia possibile effettuare il crawling del sito perché il sito potrebbe bloccare i crawl con Screaming Frog.
7/ Custom Search and Extraction
CUSTOM SEARCH
Se desideri effettuare un’analisi specifica evidenziando le pagine che presentano determinati elementi nel codice HTML, la Custom Search è un’ottima soluzione.
Esempi di utilizzo :
Per visualizzare tutte le pagine che contengono il codice UA – Google Analytics, sarebbe opportuno effettuare una ricerca tramite l’URL inserendo il codice UA nella finestra di ricerca. Questo può essere usato per vedere se in qualche pagina non è installato il codice Analytics.
Sei un blog che si occupa del tema della nascita e vorresti vedere in quali pagine compare la parola “box bébé”, per ottimizzare le pagine che la contengono o quelle che non la contengono, per posizionarti meglio su questa query. Tutto quello che devi fare è inserire nella tua finestra di ricerca personalizzata: “box bébé”.
Quindi, nella ricerca personalizzata di Screaming Frog, si vedrà questo:
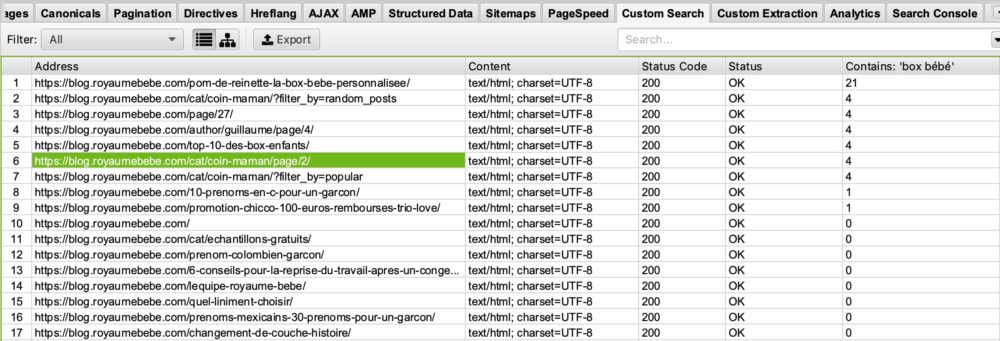
Se si guarda alla colonna ” Contains Box Bébé” si può vedere che Screaming Frog ha elencato le pagine che contengono box bébé. Ti lasciamo immaginare cosa può fare per te nelle tue ottimizzazioni SEO più avanti. 🙂
EXTRACTION
Screaming Frog, tramite la sua funzione di estrazione, può anche consentire di raccogliere alcuni dati da utilizzare per ulteriori analisi. Ad esempio, in agenzia utilizziamo sempre più spesso questo strumento per alcune analisi specifiche.
Per fare uno scraping di questi dati, è sufficiente configurare l’estrattore dicendogli cosa recuperare tramite un percorso X, un percorso CSS o regex.
Troverai tutte le informazioni per questa configurazione in questo articolo: https://www.screamingfrog.co.uk/web-scraping/
Esempi di utilizzo:
Nel caso si voglia recuperare la data di pubblicazione di un articolo per poi decidere di pulire o riottimizzare alcuni articoli, questa funzione consente di recuperare queste informazioni dall’elenco dei risultati di Screaming Frog e di esportarle, ad esempio, in Excel. Fantastico, non è vero?
Se poi si vuole esportare l’elenco dei prodotti dei concorrenti che si trovano nelle loro pagine di inserzione e sono in h2, si può semplicemente configurare l’estrattore per recuperare queste informazioni e poi giocare con i dati in Excel.
Le possibilità di utilizzo di questa funzione di estrazione sono davvero illimitate. Sta a te essere creativo e padroneggiarlo alla perfezione.
8/ API Access
In questa finestra è possibile configurare il recupero dei dati da altri strumenti configurando l’accesso all’API. Ad esempio, è possibile caricare facilmente i dati di Google Analytics, Google Search Console, Majestic SEO o Ahrefs nelle tabelle con informazioni per ogni URL. Si può dire che moltiplicherà le potenzialità della tua analisi e del tuo audit.
L’unico inconveniente è che bisogna fare attenzione ai crediti API sui vari strumenti. Potrebbero finire molto velocemente.
9/ Authentication
Alcuni siti richiedono un login e una password per accedere a tutti i contenuti. Screaming Frog consente di gestire i diversi casi di accesso tramite password e login.
CASO BASE DI AUTENTICAZIONE
Nella maggior parte dei casi non sarà necessario configurare nulla, poiché per impostazione predefinita, se Screaming Frog incontra una finestra di autenticazione, chiederà all’utente un login e una password per poter eseguire il crawl.
Questa è la finestra che dovresti vedere:
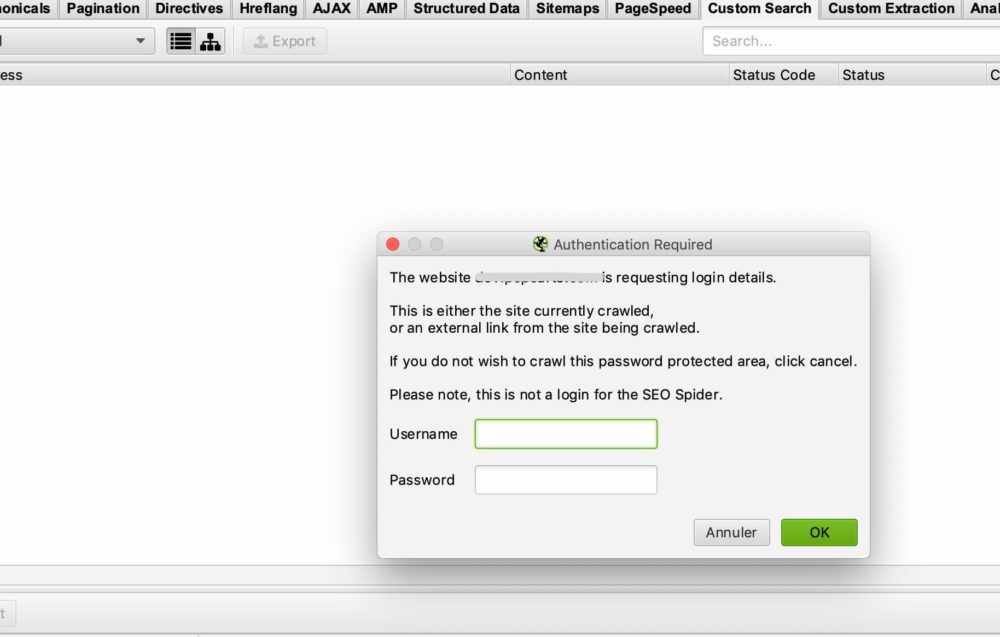
Tutto ciò che è necessario fare è inserire il proprio nome utente e la password e Screaming Frog sarà in grado di fare il crawl.
In alcuni casi può esserci un blocco tramite robots.txt. In questo caso, si dovrà fare riferimento al punto 2/ che abbiamo visto per ignorare il file robots.txt
CASO DI UN MODULO INTERNO AL SITO
Nel caso di un modulo interno al sito, è sufficiente inserire i propri dati di accesso nella sezione autenticazione > basata su modulo e quindi consentire al crawler di accedere alle pagine che si desidera analizzare.
10/ System :
STORAGE
Questa funzione è importante da padroneggiare anche nel caso in cui si debba eseguire il crawling di siti con più di 500.000 URL.
In questa finestra sono disponibili due opzioni: Memorizzazione nella memoria e Memorizzazione nel database.
Per impostazione predefinita, Screaming Frog utilizza la memoria di archiviazione, ovvero la RAM del computer per eseguire il crawling del sito. Funziona molto bene per i siti non troppo grandi. Tuttavia, si raggiungono rapidamente i limiti per i siti che superano le 500.000 URL. Il tuo computer potrebbe subire un notevole rallentamento e il crawl potrebbe richiedere molto tempo. Fidati della nostra esperienza.
Nell’altro caso si consiglia di passare allo storage del database, soprattutto se si dispone di un’unità SSD. L’altro vantaggio della memorizzazione su database è che i crawl possono essere salvati e recuperati facilmente dall’interfaccia di Screaming Frog. Anche se il crawl viene interrotto, è possibile riprenderlo. In alcuni casi, questo può davvero farvi risparmiare lunghe ore di lavoro.
MEMORY
Qui si definisce la quantità di memoria che Screaming Frog può utilizzare per funzionare. Più si aumenta la memoria, più Screaming Frog sarà in grado di eseguire il crawling di un gran numero di URLs. Soprattutto se è impostato sul Memory storage.
10/ La modalità di crawl :
SPIDER
Questa modalità è la configurazione di base di Screaming Frog. Una volta inserita l’URL, Screaming Frog seguirà i link del sito e effettuerà il crawling dell’intero sito.
LIST MODE
Questa modalità è molto utile perché consente di indicare a Screaming Frog di sfogliare un elenco specifico di URL.
Ad esempio, se si desidera controllare lo stato di un elenco di URL, è sufficiente caricare un file o copiare e incollare manualmente l’elenco di URLs.
SERP MODE
Questa modalità non prevede il crawl. Permette di caricare un file con, ad esempio, i titoli e la meta descrizione per vedere come si presenterebbe in termini di SEO. Questo può essere utilizzato, ad esempio, per verificare la lunghezza dei titoli e delle meta descrizioni dopo le modifiche apportate in Excel.
Analizzare i dati di crawl
L’interfaccia di Screaming Frog :
Prima di tuffarsi a capofitto nell’analisi dei dati presentati da Screaming Frog, è importante comprendere come è strutturata l’interfaccia
Normalmente si dovrebbe avere qualcosa di simile:
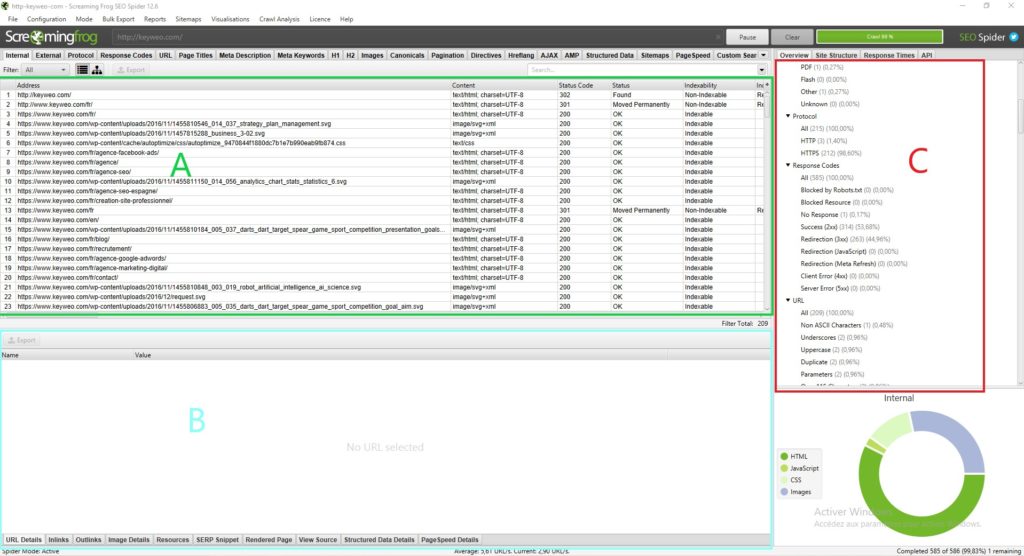
Ogni parte ha una sua utilità e ti aiuterà a non perderti in tutti i dati disponibili:
Parte A (in verde) : Questa parte corrisponde all’elenco delle risorse crawlate con, per ogni colonna, le indicazioni SEO specifiche per ogni riga. In generale, qui si trova l’elenco delle pagine e le informazioni specifiche di ogni pagina, come il codice di stato, l’indicizzabilità della pagina, il numero di parole… Questa vista cambia a seconda di ciò che si seleziona nella parte C.
Parte B (in blu) : Qui è possibile ottenere una visione più dettagliata di ogni risorsa analizzata facendo clic su di essa. Ad esempio, è possibile avere una panoramica dei collegamenti in entrata di una pagina, delle immagini e di altre informazioni che potrebbero essere molto utili.
Parte C (in rosso) :
Questa parte sarà importante da esaminare durante l’analisi, perché è qui che si potrà vedere punto per punto ciò che può essere ottimizzato e Screaming Frog ti darà anche un aiuto per facilitare la tua analisi. Esempio: Metadescrizione mancante, H1 multiplo…
Per orientarti nell’analisi dei tuoi dati, ti consigliamo di andare alla parte C.
L’overview (Parte C) :
1/ Il Summary :
In questa parte è possibile avere una visione globale del sito, compreso il numero di url del sito (immagini, html…), il numero di url esterni e interni bloccati dal robots.txt, il numero di url che il crawler è riuscito a trovare (interno ed esterno).
Questo ti fornirà informazioni preziose sul sito a colpo d’occhio.
2/ SEO Elements : Internal
In questa sezione si trovano tutte le URLs interne del sito.
HTML
Di solito è molto interessante osservare il numero di url HTML. Si può ad esempio confrontare il numero di url con il numero di pagine indicizzate su Google con il comando site: . Questo potrebbe fornire informazioni molto preziose se molte pagine non sono indicizzate su Google, ad esempio.
Facendo clic su HTML si noterà che il lato sinistro conterrà molte informazioni molto importanti da analizzare, come ad esempio :
=> Codice di stato della pagina
=> Indicizzazione
=> Informazioni sui titoli (contenuto, dimensioni)
=> Informazioni sulla meta descrizione (contenuto, dimensione)
=> Meta Keyword: non necessariamente molto utili da guardare a meno che non siano ancora utilizzate dal sito in questione. Si possono ad esempio pulire questi tag
=> H1 (Il contenuto, la dimensione, la presenza di un secondo h1 e la sua dimensione)
=> H2 (Il contenuto, la dimensione, la presenza di un secondo h2 e la sua dimensione)
=> Meta Robot
=> X Robot Tag
=> Meta refresh
=> La presenza di un’immagine canonica
=> La presenza di un tag rel next o rel prev
=> La dimensione della pagina
=> Il numero di parole nella pagina
=> Text ratio: proporzione tra testo e codice
=> Crawl Depth: la profondità della pagina in questione nel sito. La pagina iniziale si trova al livello 0 se si inizia il crawling con questa pagina. Una pagina distante 1 clic dalla home page si troverà alla profondità 1 e così via. Sapendo che è generalmente interessante ridurre questa profondità nel proprio sito
=> Inlinks / Unique inlinks : numero di link interni che puntano alla pagina in questione.
=> Outlink / Unique outlinks: numero di link in uscita da questa pagina
=> Response time: tempo di risposta della pagina
=> Redirect URL : pagina a cui la pagina viene reindirizzata se c’è un reindirizzamento
È possibile trovare tutti questi elementi anche sfogliando i diversi elementi nella colonna di destra.
Se ci si collega all’API di Search Console, Google Analytics, Ahrefs… si avranno a disposizione anche altre colonne che sarebbe molto interessante analizzare.
JAVASCRIPT, IMAGES, CSS, PDF…
Facendo clic su ogni parte è possibile ottenere informazioni interessanti su ogni tipo di risorsa presente sul sito.
3/ SEO Elements : External
La parte esterna corrisponde a tutte le URL che conducono all’esterno del tuo sito. Ad esempio, è qui che si trovano tutti i link esterni creati.
Potrebbe essere interessante analizzare le URL in uscita del tuo sito e verificarne lo stato. Se si verificano 404, sarebbe opportuno correggere il link o eliminarlo per evitare di collegarsi a pagine non funzionanti.
4/ Protocole :
In questa sezione è possibile identificare le URL HTTP e HTTPS.
Se si hanno molte URL HTTP o pagine duplicate in http e https, sarebbe utile gestire il reindirizzamento delle pagine HTTP alla loro versione HTTPS.
Se avete URL HTTP che puntano ad altri siti, potete verificare se la versione HTTP di questi siti non esiste e sostituire i link.
4/ Response Code :
La sezione Response Codes raggruppa le pagine per tipo di codice.
=> No response : Questo corrisponde di solito alle pagine che Screaming Frog non è stato in grado di esplorare.
=> Success : Qui tutte le pagine dovrebbero avere lo stato 200, cioè essere accessibili.
=> Redirection : In questa parte dovrebbero essere presenti tutte le pagine in stato 300 (301, 302, 307…) . Potrebbe essere interessante vedere come ridurre questo numero, se possibile, per inviare Google direttamente alle pagine in stato 200.
=> Client Error : Qui si troveranno tutte le pagine in errore, ad esempio con lo stato 404. Sarà importante esaminare la causa e fare un reindirizzamento.
=> Server Error :Tutte le pagine che riportano un errore del server.
5/ URL :
In questa sezione troverete l’elenco delle tue URL e i potenziali problemi o miglioramenti ad esse associati.
Sarà possibile vedere, ad esempio, le URL con lettere maiuscole o le URL duplicate.
6/ Page Titles :
Qui troverai molte informazioni sui tuoi titoli e potrai ottimizzarli per renderli molto più SEO friendly.
Ecco le informazioni che puoi trovare:
=> Missing : corrisponde alle pagine che non hanno un titolo. Pertanto, se possibile, è necessario aggiungerli.
=> Duplicate : Qui sono presenti tutti i titoli duplicati del tuo sito. L’ideale è evitare di averli. Sta a te vedere come ottimizzarli per evitare duplicazioni.
=> Over 60 Characters : Oltre un certo numero di caratteri i tuoi titoli saranno tagliati fuori dai risultati di Google. Assicurati che siano di circa 60 caratteri per evitare problemi.
=> Below 30 Characters : Qui troverai i titoli che potresti ottimizzare in termini di dimensioni. L’aggiunta di alcune parole strategiche più vicine ai 60 caratteri può consentire di ottimizzarle.
=> Over 545 Pixels / Below 200 Pixels : Un po’ come gli elementi precedenti, questo fornisce un indicazione della lunghezza dei titoli, ma questa volta in pixel. La differenza è che si possono ottimizzare i titoli utilizzando lettere con più o meno pixel per massimizzare lo spazio.
=> Same as H1 : Significa che il titolo è identico all’h1.
=> Multiple : Se hai pagine con titoli multipli, questo è il punto in cui puoi identificare il problema e vedere quali pagine devono essere sistemate.
6/ Meta description :
Come per i titoli, in questa sezione otterrai molte indicazioni per ottimizzare le tue meta descriptions in base alla loro dimensione, alla loro presenza o al fatto che siano duplicate.
7/ Meta Keywords :
Non è necessariamente utile tenerne conto, a meno che le pagine non sembrino averne molte per disottimizzarle.
Dipende da te
8/ H1 / H2 :
In queste sezioni si può vedere se ci sono ottimizzazioni da apportare ai tag Hn
Ad esempio, se nella stessa pagina sono presenti diversi h1, potrebbe valere la pena considerare di mantenerne solo uno, se ha senso. Oppure, se ci sono h1 duplicati tra le pagine, è possibile rielaborarli.
9/ Images :
Analizzando questa parte in generale, si possono trovare ottimizzazioni da effettuare sulle immagini, come ad esempio ottimizzare le immagini di dimensioni superiori a 100kb o inserire alt tags sulle immagini che ne sono prive.
10/ Canonical :
Una canonical serve a dire a Google che deve andare a tale pagina perché è l’originale. Ad esempio, se si ha una pagina con parametri e questa pagina ha contenuti duplicati della tua pagina senza parametri, si potrebbe inserire un tag canonical sulla pagina con i parametri per dire a Google che la pagina senza parametri è quella principale e che dovrebbe quindi considerare la pagina originale.
In questa parte di Screaming Frog troverai tutte le informazioni sulla gestione delle canonicals sul tuo sito.
11/ Pagination :
Qui troverai tutte le informazioni relative alla paginazione del tuo sito, in modo da poterla gestire al meglio.
12/ Directives :
La sezione Directives mostra le informazioni contenute nel tag meta robots e nell’X-Robots-Tag. Sarà possibile vedere le pagine in no index, le pagine in no follow…
13/ Hreflang :
Quando si controlla un sito multilingue, è molto importante verificare che il sito sia dotato di tag hreflang per aiutare Google a capire la lingua utilizzata nel sito, anche se si può presumere che sia sempre più in grado di capirla da solo
14/ AMP :
Le tue pagine AMP finiranno qui e potrai identificarne i problemi SEO associati.
15/ Structured data :
Per avere informazioni in questa parte è necessario attivare nella configurazione dello spider gli elementi specifici per i dati strutturati: JSON-LD, Microdata, RDFa.
Avrai così molte informazioni per ottimizzare l’implementazione dei dati strutturati sul sito.
16/ Sitemaps :
In questa sezione è possibile vedere le differenze tra ciò che è presente nel sito e nella Sitemap.
Ad esempio, è un buon modo per identificare le pagine orfane.
Per avere dati in quest’area è necessario anche abilitare la possibilità di effettuare il crawling della propria Sitemap nella configurazione del crawler e, per semplificare le cose, aggiungere il link alla propria Sitemap direttamente nella configurazione.
16/ Pagespeed :
Utilizzando l’API Page Speed Insight, è possibile identificare facilmente i problemi di velocità della pagina e risolverli analizzando i dati in questa scheda.
17/ Custom Search e Extraction :
Se si desidera eseguire lo scraping di elementi o effettuare ricerche specifiche nel codice di una pagina, è possibile trovare i dati in questo modo.
18/ Analytics et Search Console :
Collegando inoltre Screaming Frog alle API di Analytics e Search Console è possibile trovare molte informazioni utili in queste schede.
Ad esempio, qui troverai anche le pagine orfane presenti nei tuoi strumenti ma non nel crawl o le pagine con una frequenza di rimbalzo superiore al 70%.
19/ Link Metrics :
Collega Screaming Frog alle API Ahrefs e Majestic e ricava in questa parte informazioni sul netlinking delle tue pagine (esempio: Trustflow, citation flow…).
Le funzionalità addizionali di Screaming Frog
Analizzare la profondità di un sito :
Se vuoi vedere la profondità del tuo sito, può essere molto interessante guardare la scheda Site structure sul lato destro, accanto a Overview :
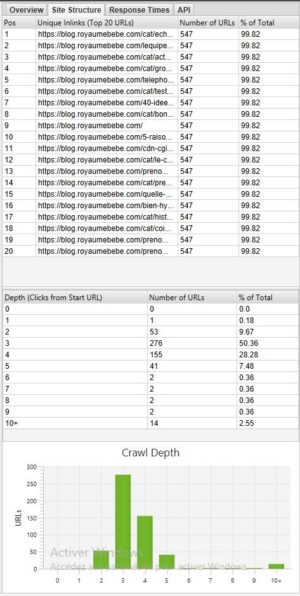
In generale è meglio avere un sito con la maggior parte delle pagine accessibili in 3 – 4 clic. Nel nostro esempio precedente, ad esempio, la profondità dovrebbe essere ottimizzata perché ci sono pagine con una profondità di 10+.
Visione spaziale del tuo :
Una volta terminato il crawl, a volte è interessante andare su Visualisations > Forced directed crawl diagram per avere una panoramica del sito sotto forma di nodo.
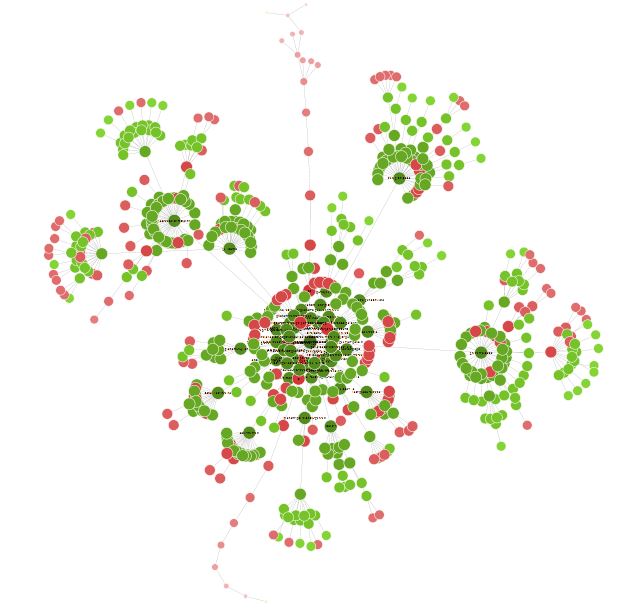
Tutti i piccoli punti rossi, ad esempio, possono essere analizzati per capire se c’è un problema o meno.
Questa visione può anche portare a riflettere sull’organizzazione del proprio sito e sui suoi collegamenti interni.
Potrai dedicare un po’ di tempo a questa visualizzazione e trovare molti modi interessanti per ottimizzare il tuo sito.
Conclusioni su Screaming Frog
Screaming Frog sarà quindi uno strumento indispensabile per una buona SEO. Lo strumento, se lo si padroneggia a fondo, permette di fare molte cose, dall’analisi SEO tecnica allo scraping dei siti.