

















Screaming Frog configuratie
Een goede configuratie van je tool is erg belangrijk om een site diepgaand te analyseren en alle gegevens te krijgen die je nodig hebt. Ontdek hoe je het stap voor stap kunt configureren
Start je eerste crawl op Screaming Frog:
Wanneer je bij de tool komt, is het eerste wat je ziet een balk waar je de URL van de site die je wilt analyseren kunt invoeren:

U hoeft alleen uw URL in te voeren en start te selecteren om uw eerste crawl te starten. Wanneer het gestart is en je wilt het stoppen, hoef je alleen maar te klikken op Pauze en dan Wissen om je crawl te resetten.
Configureer je eerste crawl op Screaming Frog:
Er zijn veel manieren om uw crawler zo in te stellen dat hij alleen informatie teruggeeft waarin u geïnteresseerd bent. Dit kan erg handig zijn wanneer u sites met veel pagina’s crawlt of wanneer u een subdomein wilt analyseren.
Ga hiervoor naar het bovenste menu en selecteer Configuratie
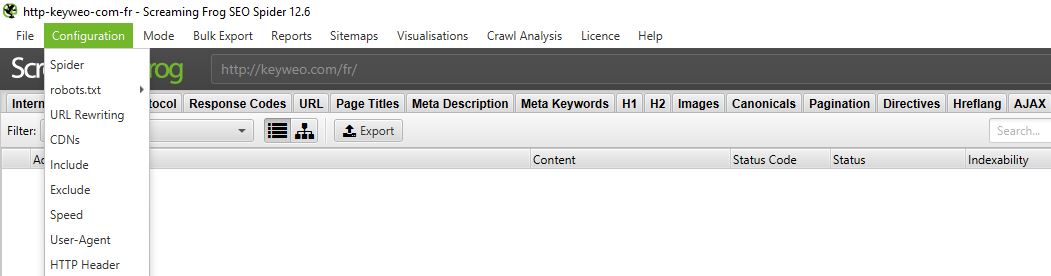
1/Spider:
CRAWL
Spider is de eerste optie die beschikbaar is wanneer u het configuratiemenu opent. Hier kunt u beslissen welke bronnen u wilt crawlen
Normaal gesproken zou je een venster moeten hebben dat er zo uitziet:
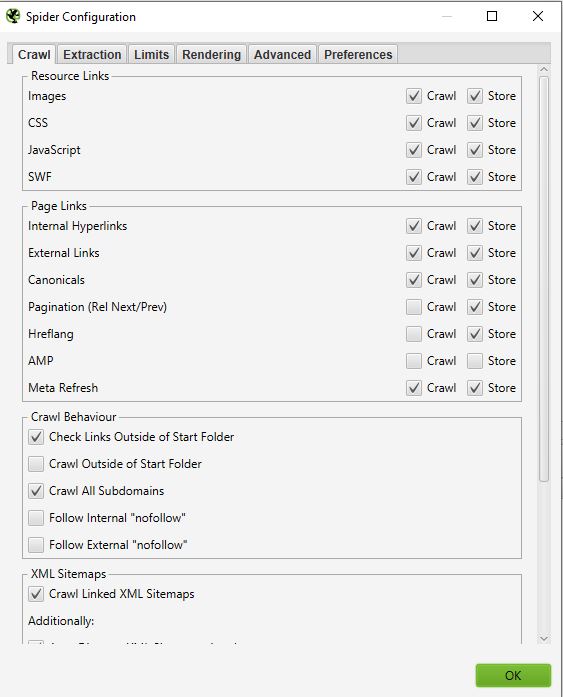
- Resources links :
U kunt bijvoorbeeld beslissen om de afbeeldingen van de site niet te crawlen. Screaming frog zal alle elementen IMG: (IMG src=”image.jpg”) uitsluiten. Uw crawl zal sneller zijn, maar u zult niet in staat zijn om het gewicht van afbeeldingen, de attributen van afbeeldingen … te analyseren.
Het is aan u om te kiezen wat u moet analyseren.
Goed om te weten: Het kan nog steeds gebeuren dat je sommige afbeeldingen hebt die naar boven komen als ze in de vorm van een href zijn en geen img src hebben.
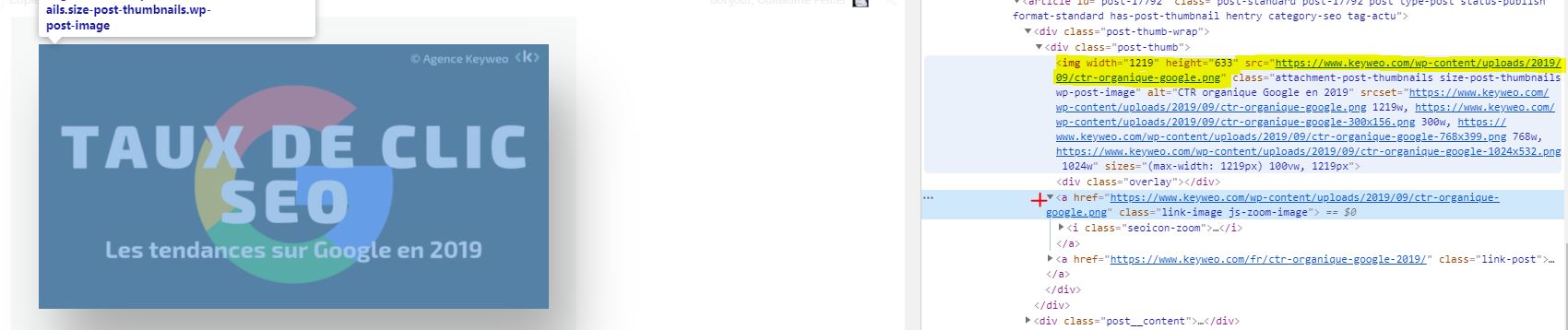
In bovenstaande schermafbeelding wordt geel niet gecrawld, en de link van de afbeelding met het rode kruis wel.
Bij de meeste van uw crawls zult u in dit venster een zeer elementaire configuratie hebben. Wij raden u aan het crawlen en opslaan van afbeeldingen, CSS, javascript en SWF-bestanden te selecteren voor een diepgaande analyse.
Pagina links:
In dit deel kunt u ook beslissen wat u wilt crawlen in termen van links. U kunt bijvoorbeeld zeggen dat u geen canonicals of externe links wilt crawlen. Nogmaals, hier is het aan u om te kiezen wat u wilt analyseren.
Voorbeeld :
Crawl met externe links en zonder externe links:
Crawl met externe links :
Crawl zonder external links :
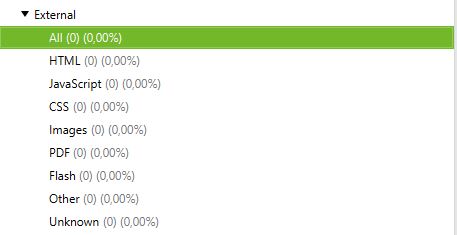
- Crawl Behaviour
In dit deel kunt u de tool instructies geven om enkele specifieke pagina’s van uw site te crawlen.
Voorbeeld :
Je hebt pagina’s in een subdomein en wilt ze allemaal op dezelfde manier crawlen om ze te analyseren. Door Crawl All Subdomains aan te vinken, zal Screaming Frog ze in zijn crawler kunnen brengen.
Hieronder zie je een site die een subdomein heeft van het type: blog. domeinnaam. Door Crawl All Subdomains te selecteren voor het starten van onze Crawl, haalt de applicatie alle URL’s van dit subdomein naar boven.

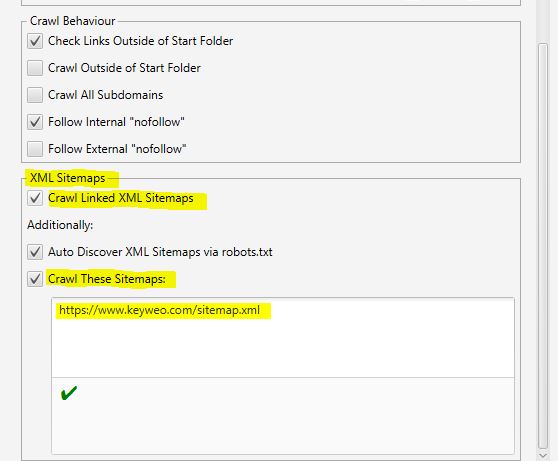
- XML Sitemaps
Heeft u een Sitemap op uw site? Dan kan het interessant zijn om de gaten te analyseren tussen wat je in je Sitemap hebt staan en de URL’s die Screaming Frog vindt.
Hier kun je Screaming Frog vertellen waar je Sitemap is, zodat het deze kan analyseren.
Hiervoor hoef je alleen maar
1- Vink “Crawl Linked XML Sitemaps” aan.
2- Vink “Crawl These Sitemaps” aan.
3- Vul de URL van je sitemap in
EXTRACTIE
In dit deel kunt u kiezen welke gegevens u wilt dat Screaming Frog uit uw site haalt en in zijn interface brengt.
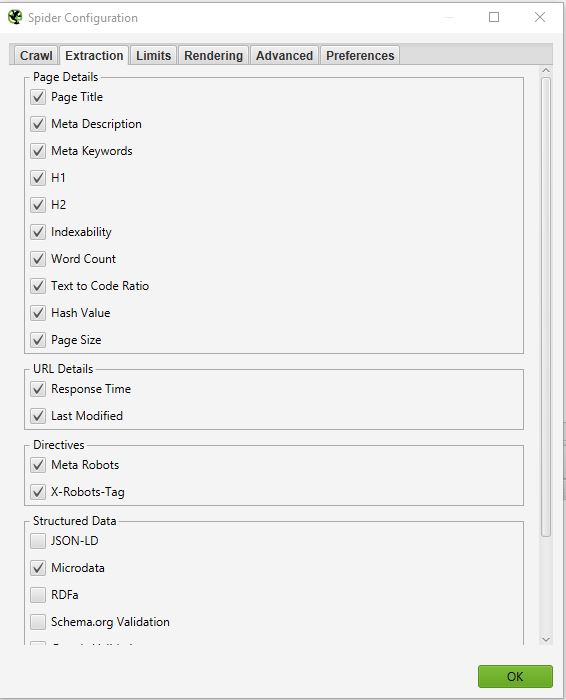
Voorbeeld:
Als u Word Count uitschakelt, heeft u niet langer het aantal woorden op elk van uw gecrawlede pagina’s.
Normaal gesproken moet u dit onderdeel niet te veel veranderen, omdat in de meeste gevallen de informatie die standaard van uw site wordt gehaald het belangrijkst is.
Als u een diepgaande SEO-audit wilt doen, kan één ding interessant zijn. Dat is om de informatie met betrekking tot gestructureerde gegevens te selecteren: JSON-LD, Microdata, RDFa, Schema.org Validatie. U krijgt dan waardevolle informatie over de implementatie van microdata op uw site.
LIMIETEN
In dit derde tabblad is het mogelijk om limieten voor de crawler in te stellen. Dit kan bijzonder nuttig zijn wanneer u sites met veel pagina’s wilt analyseren.
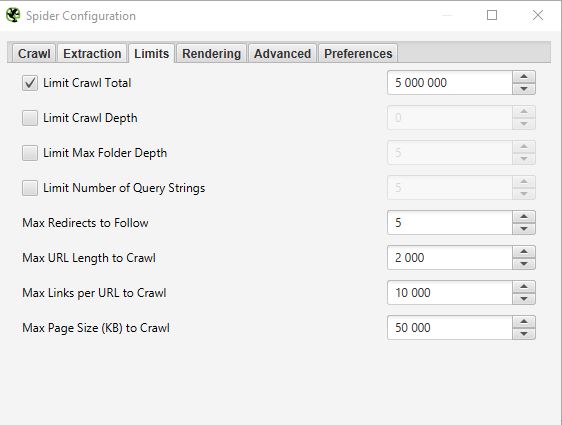
- Limiet Crawl totaal :
Dit komt overeen met het aantal URL’s dat Screaming Frog kan crawlen. In het algemeen, wanneer we een site analyseren heeft het niet noodzakelijkerwijs zin om het te beperken tot een aantal URL’s. Daarom raken we deze parameter over het algemeen niet aan.
Beperk Crawl Diepte :
Dit is de maximale diepte die u wilt dat de crawler bereikt. Niveau 1 is de pagina die één klik verwijderd is van de homepage en zo verder. Wij wijzigen deze parameter zelden omdat het interessant is om de maximale diepte van een site te bekijken bij een SEO audit. Als deze te hoog is, moeten we actie ondernemen om deze te verlagen.
Limit Max Folder Depth :
In dit geval is het de maximale mapdiepte waartoe u wilt dat de crawler toegang heeft.
Limiet aantal query string :
Sommige sites hebben parameters van het type ?x= in hun URL’s. Met deze optie kun je de crawl beperken tot URL’s die een bepaald aantal parameters bevatten.
Voorbeeld: Deze URL https://www.popcarte.com/cartes-flash/carte-invitation/invitation-anniversaire-journal.html?age=50&format=4 bevat twee parameters age= en format=. Het kan interessant zijn om de crawl te beperken tot één parameter om te voorkomen dat tienduizenden URL’s worden gecrawld.
Deze optie is zeer nuttig voor eCommerce sites met veel pagina’s en listings met cross-links.
Max redirect to Follow :
Met deze optie kunt u het aantal redirects instellen die de crawler moet volgen.
Max URL lengte om te crawlen :
Door dit veld aan te passen kunt u de lengte van de URL’s selecteren die u wilt crawlen. Aan onze kant gebruiken we dit zelden, behalve in zeer specifieke gevallen.
Max links per te crawlen URL:
Hier kun je het aantal links per URL instellen dat de Screaming Frog gaat crawlen.
Max pagina grootte om te crawlen :
Je kunt het maximale gewicht kiezen van de pagina’s die de crawler gaat analyseren.
RENDERING
Dit venster is nuttig als je een site wilt crawlen die draait op een javascript framework zoals Angular, React, etc.
Als u een dergelijke site analyseert kunt u uw crawler als volgt configureren:
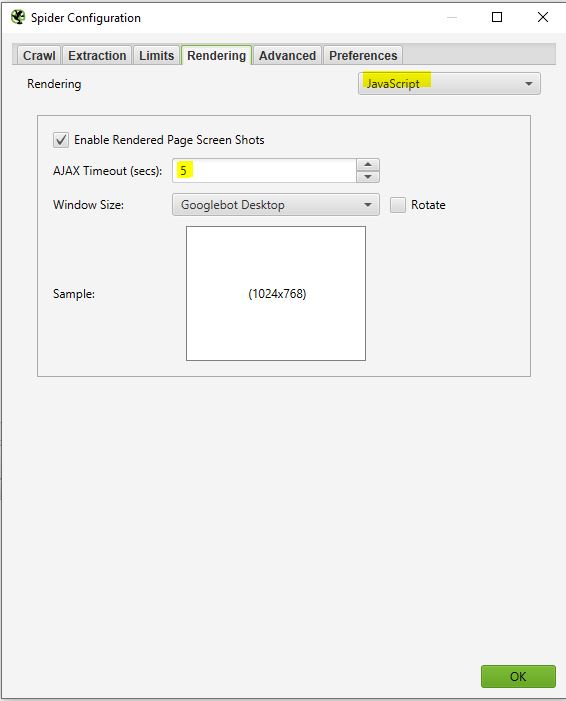
Screaming Frog zal screenshots maken van de gecrawlde pagina’s. U kunt deze vinden in uw crawl resultaat door te klikken op de URL’s die naar voren komen.
Als u ziet dat uw pagina niet optimaal rendert, kijk dan naar de geblokkeerde bronnen in het linkerframe en probeer de AJAX TIMEOUT aan te passen.
ADVANCED
Als u dit punt hebt bereikt, betekent dit dat u uw crawler al goed hebt geconfigureerd. Als u echter verder wilt gaan, kunt u nog enkele parameters beheren in dit “Geavanceerd” gedeelte.
Hier zijn enkele instellingen die nuttig kunnen zijn:
Pauze bij hoog geheugengebruik :
Screaming frog zal, wanneer het aan de limiet van zijn geheugen komt, het proces van crawlen kunnen pauzeren en u waarschuwen zodat u uw project kunt opslaan en voortzetten als u dat wenst.
Volg altijd redirect:
Deze optie is nuttig indien u redirect ketens heeft op de site die u analyseert.
Respecteer noindex, canonical en next-prev:
De crawler zal pagina’s die deze tags bevatten niet tonen in de crawlresultaten. Dit kan weer interessant zijn als u een site met veel pagina’s analyseert.
Extract afbeeldingen van img srcset attribuut :
De crawler zal de afbeeldingen met dit attribuut extraheren. Dit attribuut wordt vooral gebruikt bij responsief beheer van een site. Het is aan u om te kijken of het relevant is om deze afbeeldingen op te halen.
Response Timeout (secs) :
Dit is de maximale tijd die de crawler moet wachten tot een pagina op de site geladen is. Als deze tijd wordt overschreden, kan Screaming Frog een code 0 retourneren, wat overeenkomt met een “connection timeout”.
5xx response retries :
Dit is het aantal keren dat Screaming Frog een pagina opnieuw moet proberen in geval van een error 500.
PREFERENCES
In deze sectie kunt u definiëren wat Screaming Frog als fouten moet rapporteren.
U kunt het maximale gewicht van afbeeldingen, meta-beschrijving of een titel bepalen.
Hier is het aan u om uw SEO-strategie te bepalen volgens uw ervaring en uw wensen.
2/ Robots.txt
Gefeliciteerd dat u het zo ver heeft geschopt. Het eerste deel was niet gemakkelijk, maar is van vitaal belang voor een goede configuratie van uw crawler. Dit deel zal veel gemakkelijker zijn dan het vorige.
Door Robots.txt te selecteren uit het menu kunt u instellen hoe Screaming Frog moet omgaan met uw robots bestand.
INSTELLINGEN :
Dit zou je moeten zien als je bij de Robots instellingen komt.
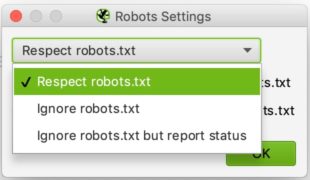
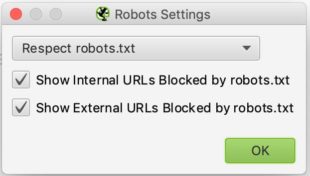
De configuratie is relatief eenvoudig. In de drop-down lijst kunt u Screaming Frog vertellen of het de aanwijzingen van het robots.txt bestand moet respecteren of niet.
Het negeren van robots.txt kan nuttig zijn, bijvoorbeeld als de site die u wilt analyseren Screaming Frog niet toestaat om te crawlen om een of andere reden. Door robots.txt te negeren, zal Screaming Frog het niet interpreteren en kun je de site in kwestie normaal crawlen.
Het respecteren van robots.txt is de meest gebruikelijke keuze en u kunt dan de twee checkboxen hieronder gebruiken om te beslissen of u de door robots.txt geblokkeerde URL’s in de rapporten wilt zien, of ze nu intern of extern zijn.
AANGEPAST :
In dit controlepaneel kunt u zelf uw robots.txt simuleren. Dit kan vooral handig zijn als u wijzigingen wilt testen en de impact wilt zien tijdens een crawl.
Merk op dat deze tests geen invloed hebben op uw online robots.txt bestand. Als je het wilt veranderen, zul je dat zelf moeten doen nadat je bijvoorbeeld je tests in Screaming Frog hebt uitgevoerd.
Hier is een voorbeeld van een test:
We hebben een regel toegevoegd om het crawlen van elke URL die /blog/ bevat te voorkomen.
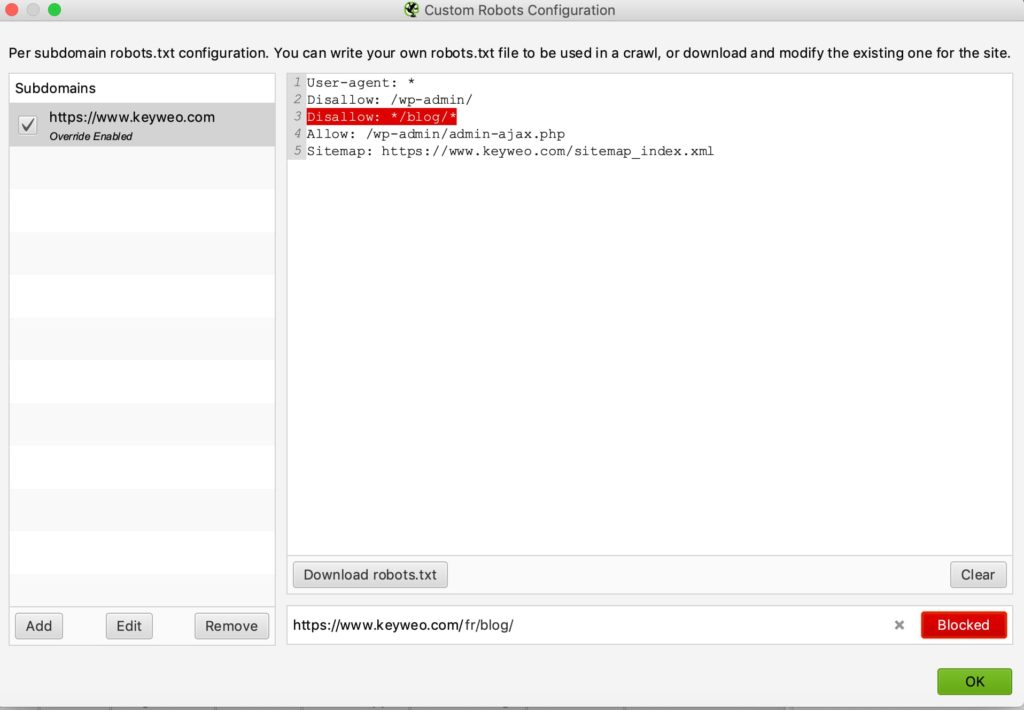
Als je hieronder kijkt zie je dat in de test die we uitvoerden met keyweo.com/fr/blog de URL inderdaad werd geblokkeerd.
3/ URL herschrijven
Deze functie is zeer nuttig wanneer uw URL’s parameters bevatten. In het geval van bijvoorbeeld een site van e-commerce met listings met filters. U kunt Screaming Frog verzoeken om de URL’s te herschrijven.
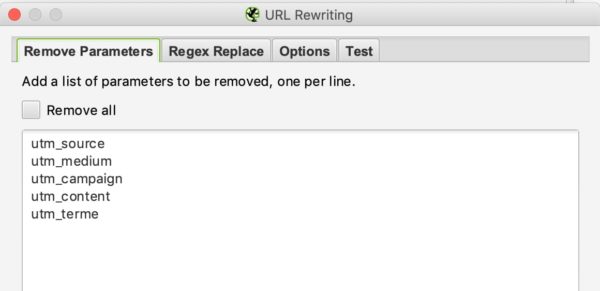
PARAMETERS VERWIJDEREN
Je kunt de crawler vertellen om sommige parameters te verwijderen om ze te negeren. Dit kan nuttig zijn voor sites met UTMs in hun URLs.
Voorbeeld :
Als je de utm parameters in je URL’s wilt verwijderen kun je deze configuratie instellen:
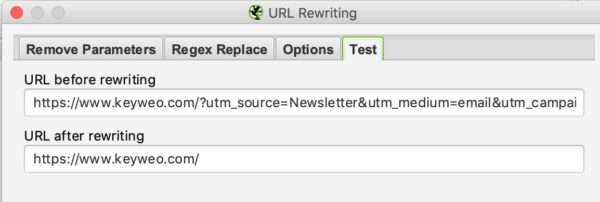
Om te testen of het werkt moet je naar de test tab gaan en een URL plaatsen die deze parameters bevat om het resultaat te zien:
REGEX VERVANGEN
In dit tabblad kunt u parameters vervangen door andere. U kunt hier vele voorbeelden vinden.
4/ Insluiten en uitsluiten
Bij Keyweo gebruiken we deze functies veel. Het is vooral handig voor sites met veel URL’s, en je wilt alleen bepaalde delen van de site crawlen. Screaming Frog kan de aanwijzingen die u maakt gebruiken om alleen bepaalde pagina’s te laten verschijnen in zijn lijst met crawlresultaten.
Als u grote sites beheert of analyseert, zal deze functie zeer belangrijk zijn om te beheersen omdat het u vele uren crawlen kan besparen.
De interface van include en exclude ziet er als volgt uit:
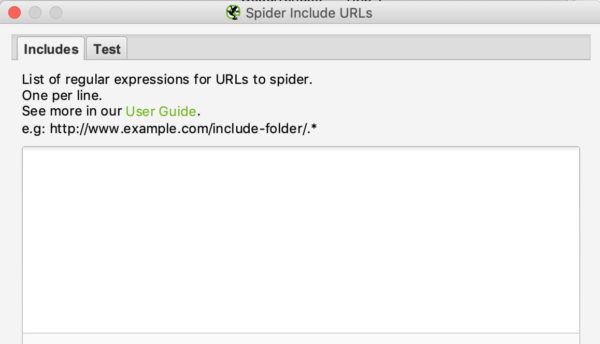
Je kunt de URL’s die je wilt in- of uitsluiten opsommen door één URL per regel in het witte vak te zetten.
Bijvoorbeeld, als ik alleen de /fr/ URL’s van Keyweo wil crawlen, is dit wat ik in mijn include venster kan zetten:
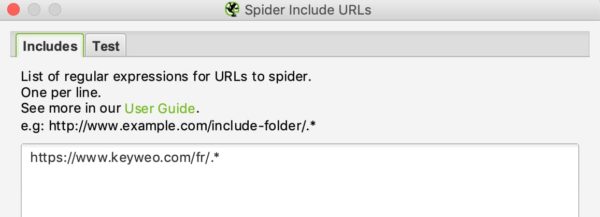
Net als bij URL-herschrijven kunt u zien of uw include werkt door een URL te testen die niet in de crawl zou moeten worden opgenomen:
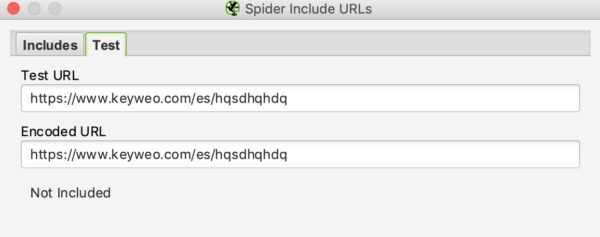
In ons bovenstaande voorbeeld zien we dat de include werkt omdat de URL’s die /es/ bevatten niet in aanmerking worden genomen.
Als u bepaalde URL’s wilt uitsluiten, is het proces vergelijkbaar.
5/ Snelheid
In dit onderdeel kun je kiezen hoe snel je wilt dat Screaming Frog de site die je wilt analyseren crawlt. Dit kan handig zijn als je grote sites wilt scannen. Als je de standaard instelling laat staan, kan het lang duren om die website te crawlen. Door de Max Threads te verhogen zal Screaming Frog de site veel sneller kunnen crawlen.
Deze configuratie moet met voorzichtigheid worden gebruikt omdat het het aantal HTTP verzoeken naar een site kan verhogen, wat de site kan vertragen. In extreme gevallen kan het er ook voor zorgen dat de server crasht of dat u geblokkeerd wordt door de server.
In het algemeen raden wij u aan deze configuratie tussen 2 en 5 Max Threads te laten.
U kunt meerdere URL’s definiëren om per seconde te crawlen.
Aarzel niet om contact op te nemen met de technische teams die de site beheren om de crawl van de site te optimaliseren en een overbelasting te vermijden.
6/ User-agent configuratie
In dit onderdeel kunt u instellen met welke user-agent u de site wilt crawlen. Standaard zal dit Screaming frog zijn, maar u kunt bijvoorbeeld de site crawlen als Google Bot (Desktop) of Bing Bot.
Dit kan bijvoorbeeld handig zijn als u de site niet kunt crawlen omdat de site crawlen met Screaming Frog blokkeert.
7/ Aangepast zoeken en extraheren
AANGEPAST ZOEKEN
Als u een specifieke analyse wilt uitvoeren door pagina’s met bepaalde elementen in hun HTML-code te markeren, zult u dol zijn op Aangepast zoeken.
Voorbeelden:
U wilt alle pagina’s oproepen die uw UA-code bevatten – Google analytics. Het kan slim zijn om een zoekopdracht uit te voeren via Screaming Frog door uw UA code in het zoekvenster te zetten. Dit kan gebruikt worden om te zien of er pagina’s zijn waar de analytics code niet is geïnstalleerd.
Je bent een blog begonnen met als thema “geboorte” en wilt zien op welke pagina’s het woord “babydoos” voorkomt, zodat je deze pagina’s kunt optimaliseren? Dat is mogelijk. Het enige wat je moet doen is in je aangepaste zoekbox zetten: “babydoos”.
Je ziet dan dus het volgende:
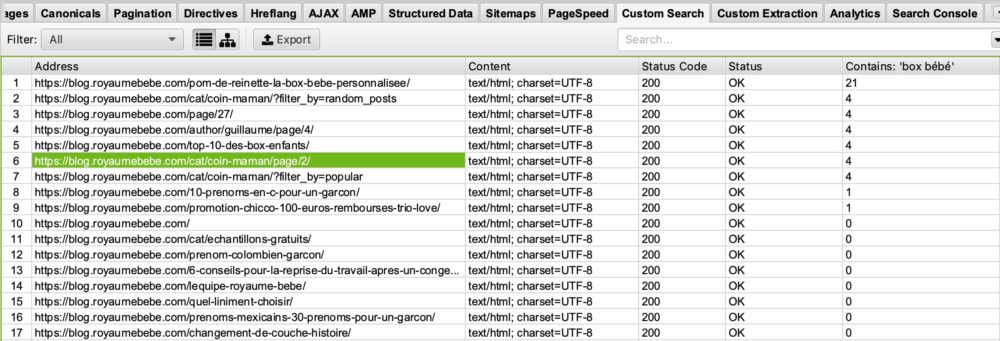
Als je kijkt in de kolom “Contains Box Bébé” zie je dat screaming frog de pagina’s die box bébé bevatten op een rijtje heeft gezet. Ik laat het aan jou over om je voor te stellen wat dit voor jou kan betekenen in je SEO optimalisaties 🙂
EXTRACTIE
Screaming Frog kan je, via zijn Extraction functie, ook toelaten om bepaalde gegevens te scrapen voor gebruik in je verdere analyse. Zo gebruiken we bij het bureau deze tool steeds meer voor bepaalde specifieke analyses.
Om deze gegevens te scrapen moet u uw extractor configureren door hem te vertellen wat hij moet ophalen via een X-pad, een CSS-pad of een regex.
U vindt alle informatie voor deze configuratie via dit artikel: https://www.screamingfrog.co.uk/web-scraping/
Voorbeelden :
Wilt u de publicatiedatum van een artikel achterhalen en vervolgens besluiten bepaalde artikelen op te schonen of opnieuw te optimaliseren? Met deze functie kunt u deze informatie uit de resultatenlijst van uw Screaming Frog halen en vervolgens exporteren naar bijvoorbeeld Excel. Geweldig, is het niet?
Wilt u de lijst met producten van uw concurrent exporteren? Ook hier kunt u uw extractor eenvoudig configureren om deze informatie op te halen en vervolgens met deze gegevens in Excel te spelen.
De mogelijkheden voor het gebruik van deze extractietool zijn onbeperkt. Het is aan u om creatief te zijn en het perfect te beheersen.
8/ API toegang
In dit venster kunt u gegevens ophalen uit andere tools door uw API-toegang te configureren. U kunt bijvoorbeeld gemakkelijk uw gegevens uit Google Analytics, Google Search Console, Majestic SEO of Ahrefs uploaden in uw tabellen met informatie voor elke URL.
Het enige nadeel is dat u moet letten op uw API-credits op uw verschillende tools, omdat ze erg snel kunnen gaan.
9/ Authenticatie
Sommige sites vereisen een login en wachtwoord om toegang te krijgen tot alle content. Met Screaming Frog kunt u de verschillende gevallen van toegang via wachtwoord en login beheren.
BASIS GEVAL VAN AUTHENTICATIE
In de meeste gevallen hoef je niets te configureren omdat standaard, wanneer Screaming Frog een authenticatie venster tegenkomt, het je zal vragen om een login en wachtwoord om de crawl uit te voeren.
Dit is het venster dat je zou moeten hebben:
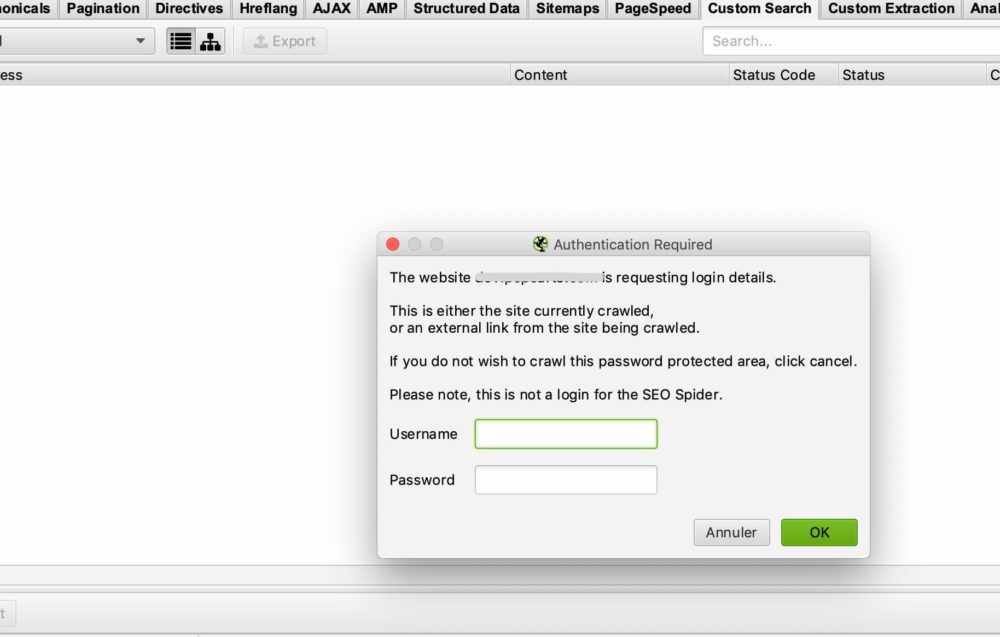
U hoeft alleen uw gebruikersnaam en wachtwoord in te voeren en Screaming Frog kan beginnen met crawlen.
In sommige gevallen kan er een blokkade zijn via de robots.txt. In dit geval moet u teruggaan naar punt 2/ om het robots.txt bestand te negeren.
GEVAL VAN EEN INTERN FORMULIER OP DE SITE
In het geval van een intern formulier op de site, kunt u gewoon uw toegangsgegevens invoeren in het op het authenticatieformulier gebaseerde gedeelte, en vervolgens de crawler toegang geven tot de pagina’s die u wilt analyseren.
10/ Systeem :
OPSLAG
Deze functie is ook belangrijk om te beheersen als u sites met meer dan 500 000 URL’s moet crawlen.
In dit venster heb je twee opties: Geheugen opslag en database Opslag
Standaard zal Screaming Frog geheugen opslag gebruiken, wat hetzelfde is als het gebruik van uw computer’s RAM om de site te crawlen. Dit werkt heel goed voor sites die niet te groot zijn. U zult echter snel de limieten bereiken voor sites met meer dan 500.000 URL’s. Uw machine kan aanzienlijk vertragen en het crawlen kan lang duren. Vertrouw op onze ervaring.
Anders raden wij u aan over te schakelen op databaseopslag, vooral als u een SSD-schijf hebt. Het andere voordeel van databaseopslag is dat uw crawls kunnen worden opgeslagen en gemakkelijk kunnen worden opgehaald uit uw screaming frog interface. Zelfs als het crawlen is gestopt, kun je het hervatten. Dit kan je in sommige gevallen lange uren crawlen besparen.
GEHEUGEN
Dit is waar je bepaalt hoeveel geheugen Screaming Frog kan gebruiken om te functioneren. Hoe meer geheugen u gebruikt, hoe meer Screaming Frog in staat zal zijn om een groot aantal URL’s te crawlen. Vooral als het is ingesteld op geheugen opslag.
10/ Crawl modus :
SPIDER
Deze modus is de basis configuratie van Screaming Frog. Zodra u uw URL invoert, zal Screaming Frog de links op uw site volgen en de gehele site crawlen.
LIJST MODUS
Deze modus is echt nuttig omdat het je toestaat om Screaming Frog te vertellen om een specifieke lijst van URLs te doorzoeken.
Bijvoorbeeld, als u de status van een lijst van URL’s wilt controleren, kunt u gewoon een bestand uploaden of uw lijst van URL’s handmatig kopiëren en plakken.
SERP-MODUS
In deze modus wordt er niet gecrawld. U kunt een bestand uploaden met bijvoorbeeld uw titels en metabeschrijving om te zien hoe het er qua SEO uit zou zien. Dit kan bijvoorbeeld worden gebruikt om de lengte van uw titels en meta description te controleren na aanpassingen in excel, bijvoorbeeld.
Analyseer uw crawlgegevens
De screaming frog interface:
Alvorens in de analyse van de door Screaming Frog gepresenteerde gegevens te duiken, is het belangrijk te begrijpen hoe de interface is gestructureerd.
Normaal gesproken zou je zoiets als dit moeten hebben:
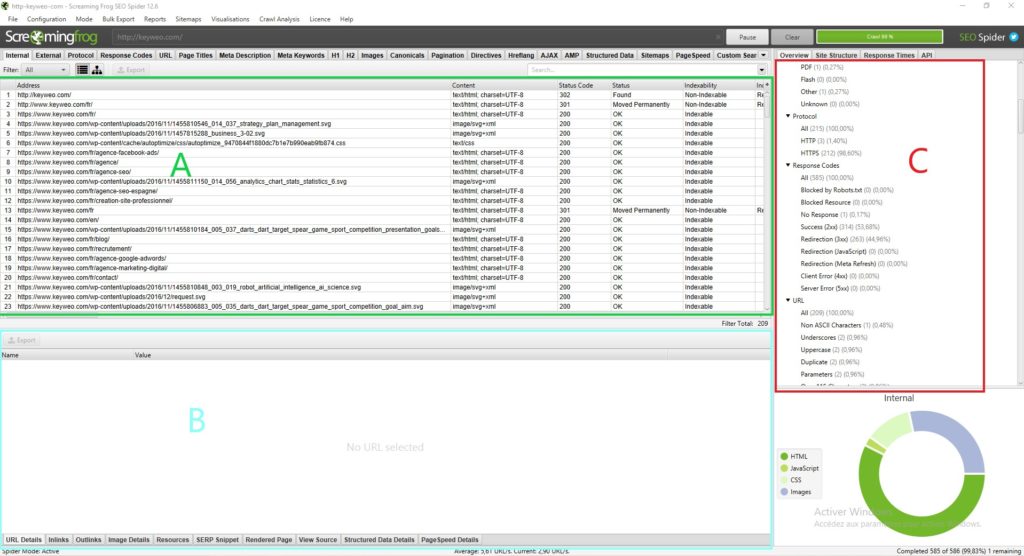
Elk deel heeft zijn nut en laat u niet verdwalen in alle beschikbare gegevens:
Deel A (in het groen): Dit deel komt overeen met de lijst van gecrawld bronnen met, voor elke kolom, SEO indicaties specifiek voor elke regel. In het algemeen vindt u hier de lijst van uw pagina’s en de specifieke informatie voor elke pagina, zoals de statuscode, de indexeerbaarheid van de pagina en het aantal woorden… Deze weergave verandert afhankelijk van wat u in deel C selecteert.
Deel B (in blauw): Hier kunt u een meer gedetailleerde weergave krijgen van elke bron die u analyseert door erop te klikken. U kunt bijvoorbeeld een overzicht krijgen van de links, afbeeldingen en andere informatie op een pagina die zeer nuttig kan zijn.
Deel C (in het rood) : Dit deel zal belangrijk zijn om naar te kijken wanneer u uw analyse doet omdat u in staat bent om te zien wat er geoptimaliseerd kan worden en Screaming Frog zal u ook wat hulp geven om uw analyse te vergemakkelijken. Voorbeeld: Metadata script ontbreekt, meerdere H1…
Om uw weg te vinden in de analyse van uw gegevens raden wij u aan naar Deel C te gaan
Het overzicht (Deel C):
1/ Samenvatting:
In dit deel krijgt u een globaal overzicht van de site, inclusief het aantal URL’s van de site (afbeeldingen, HTML…), het aantal externe en interne URL’s die door de robots.txt worden geblokkeerd, het aantal URL’s dat de crawler kon vinden (intern en extern).
Dit geeft u in één oogopslag waardevolle informatie over de site.
2/ SEO elementen: Interne
In dit onderdeel vindt u alle interne URL’s van uw site.
HTML
Het is meestal erg interessant om te kijken naar het aantal HTML URL’s. U kunt bijvoorbeeld uw aantal URL’s vergelijken met het aantal pagina’s dat op google is geïndexeerd met de opdrachtsite: Dit kan u zeer waardevolle informatie geven als veel pagina’s bijvoorbeeld niet geïndexeerd zijn op google.
Door op HTML te klikken zult u zien dat uw linkerkant veel zeer belangrijke informatie bevat om te analyseren, zoals:
=> Pagina status code
=> Indexeerbaarheid
=> Titelinformatie (content, grootte)
=> Informatie over meta description (content, grootte)
=> Meta zoekwoord: niet per se erg nuttig om naar te kijken, tenzij ze nog gebruikt worden door de site in kwestie. U zou bijvoorbeeld deze tags kunnen opschonen
=> H1 (De content, de grootte, en de aanwezigheid van een tweede h1 en de grootte ervan)
=> H2 (de content, de grootte, de aanwezigheid van een tweede h2 en de grootte ervan)
=> Meta Robots
=> X Robots Tag
=> Meta vernieuwen
=> De aanwezigheid van een canonical
=> de aanwezigheid van een rel next of rel prev tag
=> De grootte van de pagina
=> Het aantal woorden op de pagina
=> De tekstratio: verhouding tussen tekst en code
=> Crawl Depth : De diepte van de betreffende pagina op de site. De homepage staat op niveau 0 als je met deze pagina begint te crawlen. Een pagina die 1 klik verwijderd is van de home page komt op diepte 1 en zo verder. Wetende dat het over het algemeen interessant is om deze diepte in uw site te verminderen
=> Inlinks / Unique Links: aantal interne links die naar de betreffende pagina verwijzen
=> Outlinks / Unieke Outlinks: aantal uitgaande links vanaf deze pagina
=> Reactietijd: reactietijd van de pagina
=> Redirect URL: pagina waarnaar de pagina wordt doorverwezen
U kunt al deze elementen ook vinden door in de rechterkolom door de verschillende elementen te bladeren.
Als u de API van de Search Console, Google Analytics, Ahrefs… aansluit, krijgt u ook andere kolommen ter beschikking die zeer interessant zijn om te analyseren.
JAVASCRIPT, AFBEELDINGEN, CSS, PDF…
Door op elke sectie te klikken krijgt u interessante informatie over elk type bron op uw site.
3/ SEO elementen: Externe
Het externe deel komt overeen met alle URL’s die buiten uw site leiden. Hier vindt u bijvoorbeeld alle externe links die u maakt.
Het kan interessant zijn om de uitgaande URL’s van uw site te analyseren en hun status te bekijken. Als u 404’s hebt, kan het verstandig zijn uw link te corrigeren of te verwijderen om te voorkomen dat u naar gebroken pagina’s linkt.
4/ Protocol:
In dit onderdeel kunt u HTTP en HTTPS URL’s identificeren.
Als je HTTP URL’s of dubbele pagina’s in HTTP en HTTPS hebt, zou het nuttig zijn om de omleiding van je HTTP pagina’s naar hun HTTPS versie te beheren.
Een ander punt is als u HTTP URL’s hebt die naar andere sites verwijzen, kunt u controleren of de HTTPS-versie van deze sites niet bestaat en de links vervangen.
4/ Response Code :
De sectie Response Codes groepeert uw pagina’s per codetype.
=> Geen antwoord: Dit komt over het algemeen overeen met pagina’s die de Screaming Frog niet kon crawlen.
=> Succes: Al uw pagina’s zouden hier status 200 moeten hebben, d.w.z. ze zijn toegankelijk
=> Redirection: Deze sectie zou alle pagina’s met status 300 (301, 302, 307…) moeten bevatten. Het kan interessant zijn om te kijken hoe je dit aantal zo mogelijk kunt verminderen om google direct naar pagina’s met status 200 te sturen
=> Client Error: Hier zijn alle pagina’s in error met een status van bijvoorbeeld 404. Het zal belangrijk zijn om naar de oorzaak te kijken en een redirect uit te voeren.
=> Server Error: Alle pagina’s met een server error
5/ URL :
In deze rubriek vindt u de lijst van uw URL’s en de mogelijke problemen of verbeteringen die ermee gepaard gaan.
U kunt bijvoorbeeld zien of uw URL’s een hoofdletter hebben of dat er dubbele URL’s zijn.
6/ Paginatitels :
Hier krijgt u veel informatie over uw titels en kunt u ze optimaliseren om ze veel SEO-vriendelijker te maken.
Hier is de informatie die u kunt vinden:
=> Ontbreekt: Dit komt overeen met uw pagina’s die geen titel hebben. U moet ze dus toevoegen indien mogelijk
=> Duplicaat: Hier vindt u alle dubbele titels van uw site. Idealiter vermijdt u die. Het is aan u om te kijken hoe u ze kunt optimaliseren om duplicatie te voorkomen.
=> Meer dan 60 tekens: Boven een bepaald aantal tekens worden uw titels afgekapt in de Google-resultaten. Zorg ervoor dat ze rond de 60 tekens zijn om problemen te voorkomen.
=> Onder de 30 tekens: Hier vindt u de titels die u qua grootte zou kunnen optimaliseren. Door een paar strategische woorden dichter bij de 60 tekens toe te voegen, kunt u ze optimaliseren
=> Meer dan 545 pixels / Minder dan 200 pixels: Net als de vorige elementen geeft dit de lengte van uw titels aan, maar deze keer in pixels. Het verschil is dat u uw titels kunt optimaliseren door letters met meer of minder pixels te gebruiken om de ruimte te maximaliseren.
=> Zelfde als H1 : Dit betekent dat uw titel identiek is aan uw H1
=> Meerdere : Als u pagina’s heeft met meerdere titels, kunt u hier het probleem identificeren en zien welke pagina’s moeten worden opgelost.
6/ Meta Description :
Volgens hetzelfde model als de titels, heeft u in dit gedeelte vele instructies om uw meta beschrijving te optimaliseren op basis van hun grootte, hun aanwezigheid, of het feit dat ze dubbel zijn.
7/ Meta Trefwoorden :
Het is niet per se nuttig om ze te overwegen, tenzij de pagina’s er veel van lijken te hebben.
Het is aan u.
8/ H1 / H2 :
In deze secties kunt u zien of er optimalisaties moeten worden aangebracht in uw Hn-tags.
Bijvoorbeeld, als je meerdere h1’s op dezelfde pagina hebt, kan het interessant zijn om er maar één te behouden. Of als je dubbele h1’s op je pagina’s hebt, zou je ze kunnen herwerken.
9/ Afbeeldingen :
Door deze sectie in het algemeen te analyseren, kunt u optimalisaties voor uw afbeeldingen vinden, zoals het herwerken van afbeeldingen van meer dan 100kb of het plaatsen van alt-symbolen op afbeeldingen die deze niet hebben.
10/ Canoniek :
Een canonical wordt gebruikt om google te vertellen dat het naar een bepaalde pagina moet gaan omdat het het origineel is. Bijvoorbeeld, je hebt een pagina met parameters en deze pagina heeft dubbele content van je pagina zonder parameters. Je zou een canonical op de pagina met parameters kunnen zetten om google te vertellen dat de pagina zonder parameters de belangrijkste is en dat het in plaats daarvan de originele pagina moet overwegen.
In dit deel van screaming frog krijgt u alle informatie over hoe u de canonicals op uw site kunt beheren.
11/ Pagination :
Hier krijg je alle informatie over de paginering op je site zodat je die beter kan beheren.
12/ Richtlijnen :
Het onderdeel Directives toont de informatie in de meta robots tag en X-Robots-Tag. U ziet de pagina’s in no index, de pagina’s in no follow, etc.
13/ Hreflang :
Bij een audit van een meertalige site is het heel belangrijk om na te gaan of de site hreflang-tags heeft om Google te helpen de op de site gebruikte taal te begrijpen, ook al kan men ervan uitgaan dat Google zelf steeds beter in staat is deze taal te begrijpen.
14/ AMP :
Uw AMP-pagina’s komen hier terecht en u kunt de bijbehorende SEO-problemen identificeren.
15/ Gestructureerde gegevens :
Om informatie in deze sectie te hebben, moet u in uw spiderconfiguratie de elementen activeren die specifiek zijn voor gestructureerde gegevens: JSON-LD, Microdata en RDFa.
U zult veel informatie hebben om uw implementatie van gestructureerde gegevens op de site te optimaliseren.
16/ Sitemaps :
In dit deel kunt u de verschillen zien tussen wat u op uw site en in uw Sitemap heeft staan.
Het is bijvoorbeeld een goede manier om uw verweesde pagina’s te identificeren.
Om gegevens in dit deel te hebben moet u ook de mogelijkheid om uw Sitemap te crawlen inschakelen in de crawlerconfiguratie. Om het eenvoudiger te maken kunt u de link naar uw Sitemap direct in de configuratie toevoegen.
16/ Pagespeed :
Met behulp van de page speed insight API kunt u eenvoudig de snelheidsproblemen van uw pagina’s identificeren en verhelpen door de gegevens in dit tabblad te analyseren.
17/ Custom Search et Extraction :
Als u elementen wilt scrapen of specifieke zoekopdrachten wilt uitvoeren in de code van een pagina, is dit de plek om de gegevens te vinden.
18/ Analytics et Search Console :
Je kunt veel nuttige informatie vinden in deze tabbladen door ook Screaming Frog te verbinden met de Analytics en Search console API.
Je kunt bijvoorbeeld ook de weespagina’s vinden die aanwezig zijn in je tools maar niet in de crawl of de pagina’s met een bounce rate hoger dan 70%.
19/ Link Metrics :
Verbind Screaming Frog met Ahrefs en Majestic API’s en breng informatie over de linkbuilding van uw pagina’s (voorbeeld: Trustflow, citatiestroom…).
Extra kenmerken van Screaming Frog
Analyseer de diepte van een site:
Als u de diepte van uw site wilt zien, kan het heel interessant zijn om naar het tabblad Site-structuur te gaan.
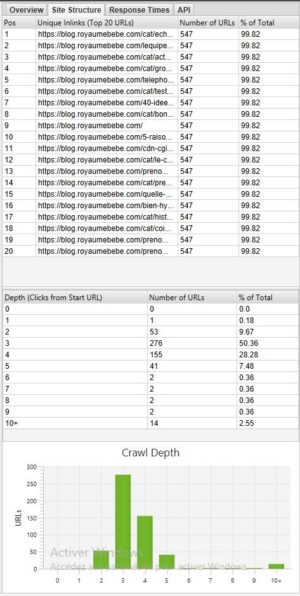
In het algemeen is het beter om een website te hebben waar de meeste pagina’s toegankelijk zijn in 3 – 4 klikken. In ons voorbeeld hierboven moeten we de diepte optimaliseren omdat er pagina’s zijn die in 10+ klikken toegankelijk zijn.
Visualisatie van uw site:
Zodra uw crawl klaar is, kan het interessant zijn om naar Visualisaties > Gedwongen gerichte crawl diagram te gaan om een overzicht van uw site te hebben in de vorm van een grafiek.
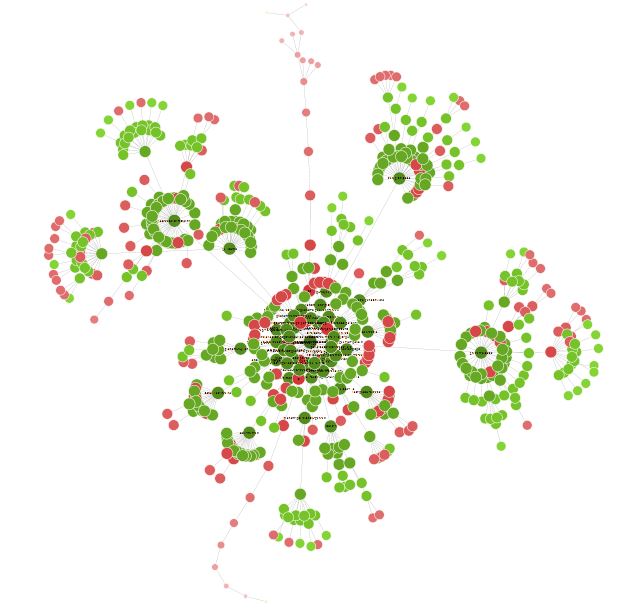
Alle kleine rode puntjes kunnen worden geanalyseerd om te begrijpen of er een probleem is of niet.
Deze visualisatie kan er ook toe leiden dat u de structuur van uw site en de interne links heroverweegt.
U kunt enige tijd doorbrengen met deze visualisatie om veel interessante optimalisatiemogelijkheden te vinden.
Conclusie Screaming Frog
Screaming Frog zal dus een onmisbaar hulpmiddel zijn voor elke goede SEO. Met de tool kun je veel dingen doen, van technische SEO-analyse tot site scraping.