

















Configuración de Screaming Frog
Una buena configuración de la herramienta será un punto importante para analizar un sitio en profundidad y obtener todos los datos que necesita. Averigua paso a paso cómo configurarlo para sacarle el máximo provecho.
Lanza tu primer crawl Screaming Frog:
Cuando llegue a la herramienta lo primero que verá es una barra en la que puede introducir la url del sitio que desea analizar:

Sólo tiene que rellenar la URL y seleccionar «start» para lanzar el primer Crawl. Una vez lanzado, si quiere detenerlo, sólo tiene que hacer clic en Pausa y luego en Borrar para restablecer el rastreo en 0.
Configura Screaming Frog SEO Spider:
Hay muchas maneras de configurar el rastreador para que sólo muestre la información que realmente le interesa. Esto puede ser muy útil, por ejemplo, cuando se rastrean sitios con muchas páginas o simplemente quiere analizar un subdominio.
Para ello, vaya al menú superior y seleccione Configuración.
1. Spider
CRAWL
El spider es la primera opción disponible cuando ingresa al menú de configuración. Aquí es donde puede decidir qué recursos quiere rastrear.
Normalmente debería tener una ventana que se vea así:
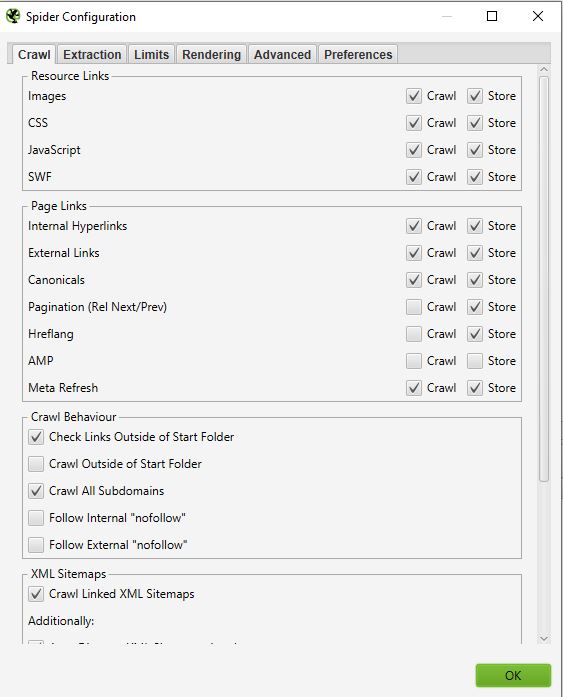
- Enlaces de recursos:
Por ejemplo, puede decidir no rastrear las imágenes del sitio, entonces, Screaming Frog excluirá así de su rastreo todos los elementos de la imagen: (img src=»image.jpg»). Su rastreo será entonces más rápido pero no podrá realizar ningún análisis sobre el peso de las imágenes, los atributos de las imágenes, etc.
Eso dependerá de lo que se quiera analizar.
Es bueno saberlo: Puede suceder que tengas algunas imágenes que se remontan si están en forma de href y no tienen un img src
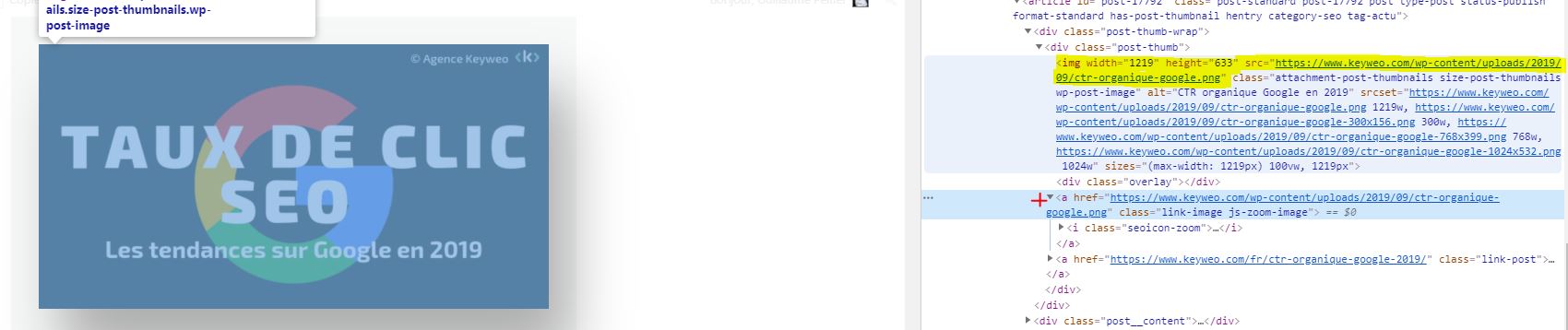
En la captura de pantalla de arriba, lo que está en amarillo no se rastreará, pero el enlace de la imagen con la cruz roja seguirá rastrándose.
En la mayoría de sus rastreos tendrá una configuración bastante básica en esta ventana. Recomendamos que compruebe el rastreo y almacenamiento de imágenes, css, javascript y archivos SWF para un análisis en profundidad.
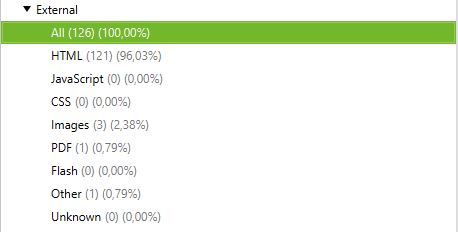
- Enlaces de la página:
En esta parte también puede decidir qué se quiere rastrear en términos de enlaces. Puede decir, por ejemplo, que no quiere rastrear por las canónicas o los enlaces externos.
Por ejemplo:
Rastrear con enlaces externos y sin enlaces externos:
- Comportamiento de Crawl:
En esta parte puede dar instrucciones a la herramienta para rastrear páginas específicas de su sitio.
Por ejemplo:
Tiene páginas de sub-dominio y todavía quiere rastrearlas para analizarlas. Al marcar la opción de rastrear todos los subdominios, Screaming Frog podrá rastrear estas páginas si hay un enlace a ellas en su sitio.
A continuación puedes ver un sitio que tiene un subdominio como: blog.domainname. Seleccionando crawl todos los subdominios antes de lanzar nuestro Crawl, la aplicación también muestra todas las urls de este subdominio.

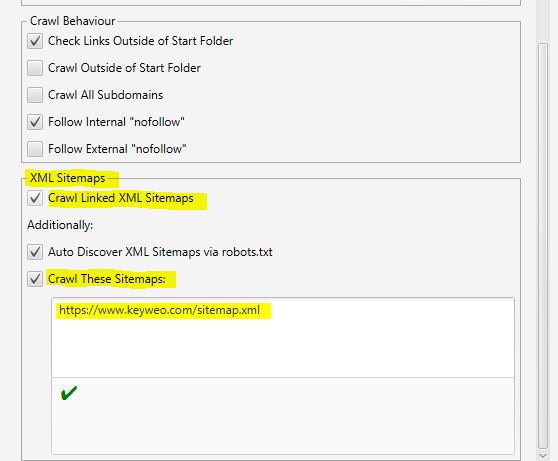
- XML Sitemaps
¿Tiene un mapa del sitio en su sitio? Entonces podría ser interesante analizar los huecos entre lo que tiene en su sitemap y las urls que encuentra Screaming Frog.
Aquí es donde puede decirle a Screaming Frog dónde está el sitemap para que pueda analizarlo.
Todo lo que tiene que hacer es:
1- Verifique los mapas de sitio XML vinculados al rastreo.
2- Revise el rastreo de estos sitemap.
3- Rellene la url de su sitemap.
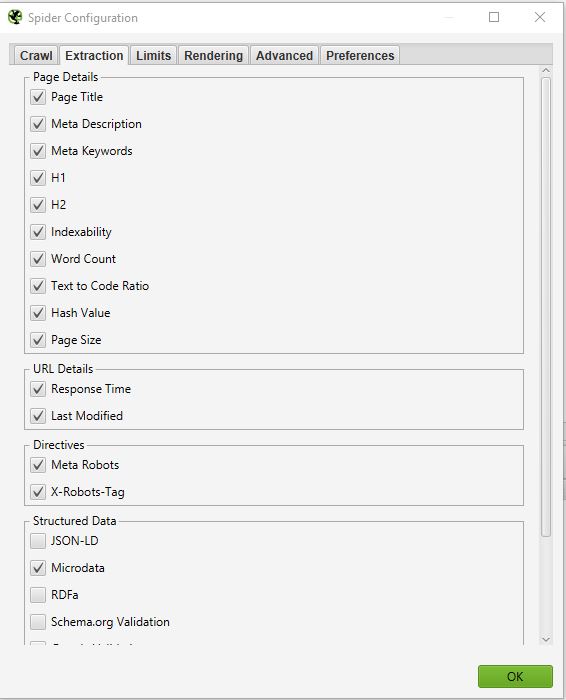
EXTRACCIÓN
En esta parte podrás elegir qué datos quieres que Screaming Frog extraiga de tu sitio y volver a su interfa
Por ejemplo:
Si desmarca Conteo de Palabras, ya no tendrá el número de palabras en cada una de sus páginas rastreadas.
Normalmente no debería modificar demasiado esta parte porque en general la información extraída de su sitio que se selecciona por defecto es la principal.
Una cosa que a veces puede ser interesante si se quiere hacer una auditoría SEO en profundidad es seleccionar la información relacionada con los datos estructurados: JSON-LD, Microdatos, RDFa, Validación de Schema.org.
Podrá obtener información valiosa sobre la implementación de microdatos en su sitio, como: páginas que no tienen microdatos, errores asociados, tipos de microdatos por página, etc…
LÍMITES
En esta tercera pestaña se pueden definir los límites para el crawl. Esto puede ser particularmente útil cuando se quiere analizar sitios con muchas páginas.
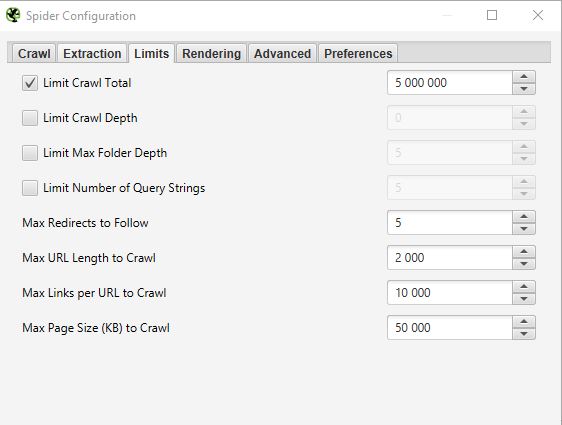
- Límite de arrastre total:
Número de urls que Screaming Frog puede rastrear. En general, cuando analizamos un sitio, no tiene necesariamente sentido limitarse a un cierto número de urls. Por eso no solemos tocar este parámetro.
- Límite de profundidad de rastreo:
Máxima profundidad que quiere que alcance el crawler. Siendo el nivel 1 las páginas a un click de la página principal y así sucesivamente. Casi nunca cambiamos este parámetro porque es interesante mirar la profundidad máxima de un sitio en una auditoría SEO. En caso de que sea demasiado profundo, tendremos que llevar a cabo acciones asociadas para reducirlo.
- Límite de profundidad máxima de la carpeta:
En este caso, es la profundidad máxima de la carpeta a la que quiere que el rastreador tenga acceso.
- Limitar la cadena de consulta del número:
Algunos sitios pueden tener en sus urls parámetros de tipo ?x=… . Esta opción le permitirá limitar el rastreo a las urls que contengan un cierto número de parámetros.
Ejemplo: La siguiente url https://www.popcarte.com/cartes-flash/carte-invitation/invitation-anniversaire-journal.html?age=50&format=4 contiene dos parámetros age= y format= . Podría ser interesante limitar el rastreo a un solo parámetro para evitar el rastreo de decenas de miles de urls.
Esta opción también es muy útil para los sitios de comercio electrónico con muchas páginas y listas de enlaces cruzados.
- Max redirección a Follow:
Esta opción permite definir el número de redirecciones que quiere que tu crawler siga.
- Máximo de enlaces por URL para rastrear:
Aquí puede controlar el número de enlaces por url que la Screaming Frog podrá rastrear.
- Tamaño máximo de la página a rastrear:
Aquí puede elegir el peso máximo de las páginas que su rastreador podrá analizar.
RENDIMIENTO
Esta ventana será particularmente útil si quiere, por ejemplo, rastrear un sitio que funciona con un marco de javascript como Angular, React, etc…
Si está escaneando un sitio de este tipo puede configurar su rastreador de esta manera:
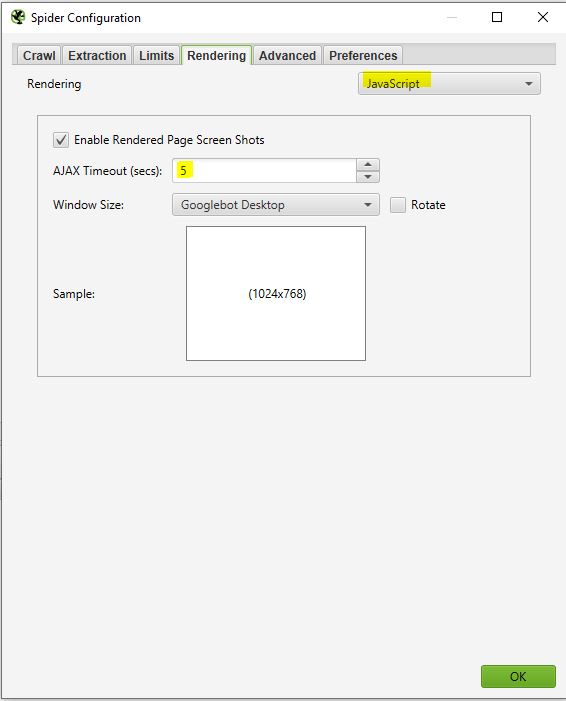
Screaming Frog tomará capturas de pantalla de las páginas rastreadas que puede encontrar en el resultado de su rastreo haciendo clic en las url ascendentes y seleccionando la página renderizada.
Si ve que el renderizado de su página no es óptimo en esta parte, mire los recursos bloqueados en el cuadro de la izquierda y puede intentar modificar el AJAX TIMEOUT.
AVANZADO
Si ha llegado a este punto, quiere decir que ya tiene una buena configuración del crawler. Sin embargo, si quiere ir más lejos, todavía puede manejar algunos parámetros en esta parte «Avanzada».
Aquí hay algunas configuraciones que podrían ser útiles:
- Pausa en el uso de la memoria alta:
Esta opción está pre marcada por defecto en el panel de control de la Screaming Frog. Será particularmente útil y puede ser activada cuando se rastrean grandes sitios. En efecto, Screaming Frog cuando llega al límite de su memoria puede detener el proceso de rastreo y avisarle para que pueda guardar su proyecto y continuarlo si lo desea.
- Siempre sigue la redirección:
Esta opción es útil en caso de que tenga cadenas de redireccionamiento en el sitio que está escaneando actualmente.
- Respetar el noindex, el canon y el next-prev:
El rastreador en este caso no le mostrará en los resultados de su rastreo de las páginas que contienen estas etiquetas. Esto puede ser de nuevo interesante si estás rastreando un sitio con muchas páginas.
- Extraer imágenes del atributo img srcset:
El rastreador en este caso extraerá imágenes con este atributo. Este atributo se utiliza principalmente en los casos de gestión de respuesta de un sitio. Depende de usted ver si es relevante recuperar estas imágenes.
- Tiempo de respuesta (segundos):
Este es el tiempo máximo que el rastreador tendrá que esperar para que una página se cargue en el sitio. Si se supera este tiempo, Screaming Frog será capaz de devolver un código 0 correspondiente a un «tiempo de espera de la conexión».
- 5xx reintentos de respuesta:
Este es el número de veces que Screaming Frog debe volver a probar una página en caso de error 500.
PREFERENCIAS
En esta parte podrá definir realmente qué Screaming Frog debe subir por error.
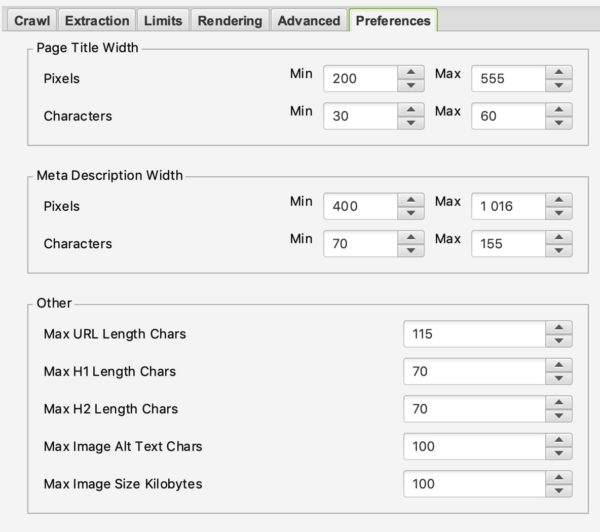
Por ejemplo, se puede definir el peso máximo de las imágenes en las que esto puede considerarse un problema, o el tamaño máximo de una meta descripción o título.
Aquí depende de ti definir tus reglas de SEO de acuerdo a tu experiencia y tus deseos.
2. Robots.txt
Felicitaciones por haber llegado hasta aquí. La primera parte no era obvia, pero será vital para una buena configuración de su crawler. Esta parte será mucho más simple que la anterior.
Seleccionando Robots.txt en el menú podrá configurar cómo Screaming frog debe interactuar con su archivo de robots.
AJUSTES:
Normalmente deberías ver esto cuando llegues a la sección de configuración de los robots
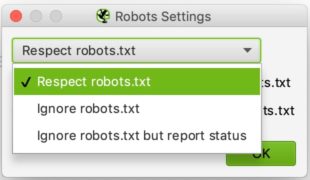
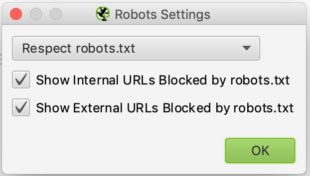
La configuración aquí es relativamente simple. En la lista desplegable puede decirle a Screaming Frog si debe seguir o no las instrucciones del archivo robots.txt.
El caso de ignorar el robots.txt podría ser útil, por ejemplo, si el sitio que se quiere explorar no permite que Screaming lo rastree por alguna razón. Seleccionando ignorar robots.txt, Screaming Frog no lo interpretará y normalmente podrá rastrear el sitio en cuestión.
El caso del respeto al robots.txt es el caso más recurrente y podemos entonces decir con las dos casillas de verificación de abajo si queremos ver en los informes las urls bloqueadas por el robots.txt ya sean internas o externas.
A MEDIDA:
En este panel de control puede simular su robots.txt. Esto puede ser particularmente útil si quiere probar las modificaciones y ver el impacto de un crawl.
Tenga en cuenta que estas pruebas no afectarán a su archivo robots.txt que está en línea. Si quiere modificarlo tendrá que hacerlo usted mismo después de haber hecho las pruebas en Screaming frog.
Aquí le dejamos un ejemplo de prueba:
Hemos añadido una línea para evitar que se arrastre cualquier url que contenga /blog/.
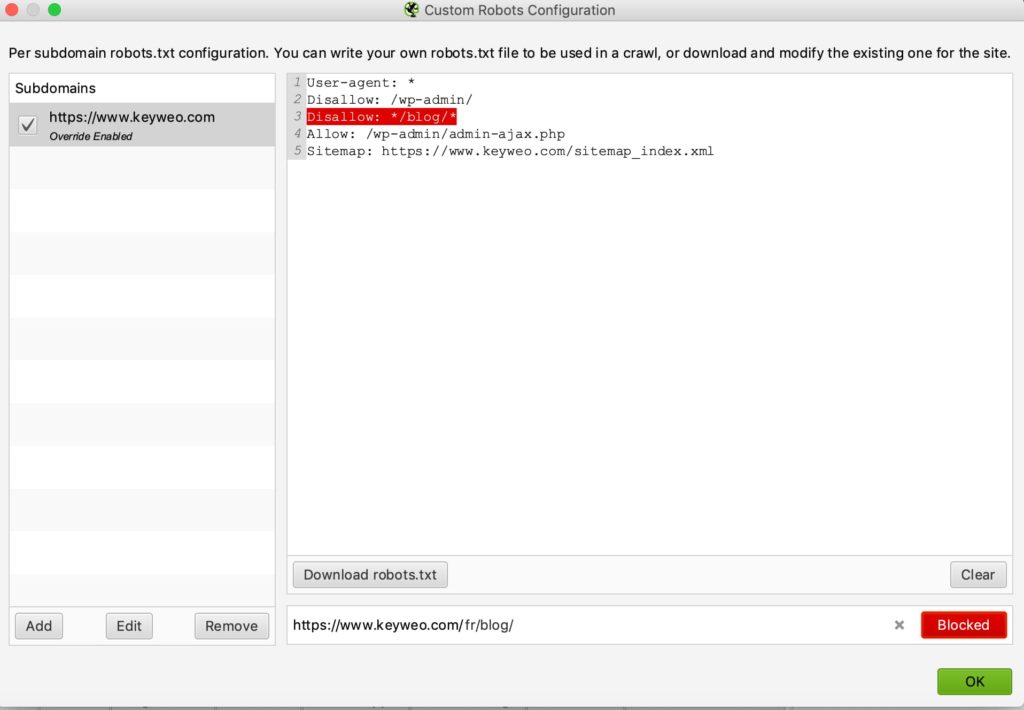
Si miras abajo verás que durante la prueba que hicimos con keyweo.com/es/blog la url se bloqueó.
3. Reescritura de URL
Esta característica será muy útil en caso de que sus urls contengan parámetros. En el caso, por ejemplo, de un sitio de e-commerce con un listado con filtros. En esta parte puedes pedirle a la Screaming frog que reescriba las url en vol.
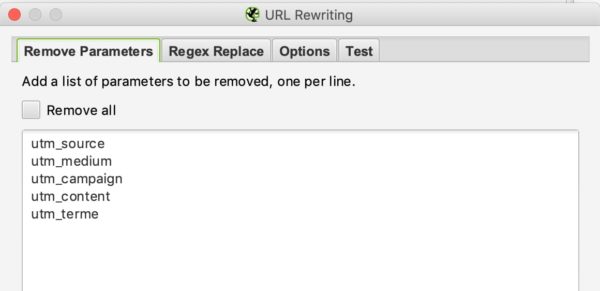
ELIMINAR LOS PARÁMETROS…
Podrás decirle al rastreador de esta parte que elimine algunos parámetros para ignorarlos. Esto podría ser particularmente útil para los sitios con UTM en sus urls.
Por ejemplo:
Si queremos eliminar los parámetros de la utm en nuestras urls puede poner esta configuración:
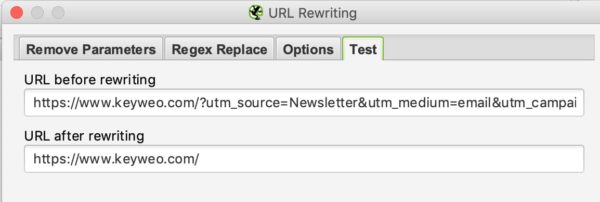
Luego, para comprobar si funciona, sólo tiene que ir a la pestaña de pruebas y poner una url que contenga estos ajustes para ver cómo se ve:
REEMPLAZO DEL RÉGIMEN
En esta pestaña podrá reemplazar algunos ajustes sobre la marcha con otros. Puede encontrar muchos ejemplos en la documentación de Screaming Frog aquí.
4. Incluir y excluir
En Keyweo usamos mucho estas características. Esto es especialmente útil para los sitios con muchas url si sólo quiere rastrear ciertas partes del sitio. Screaming Frog podrá usar las indicaciones que haga en estas ventanas para que sólo aparezcan ciertas páginas en su lista de resultados del rastreo.
Si administra o analiza sitios grandes, esta característica será muy importante de dominar para ahorrarle muchas horas de rastreo.
La interfaz de inclusión y exclusión es la siguiente:
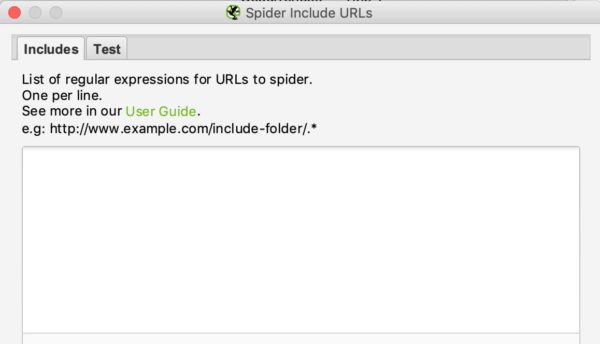
Podrá enumerar las urls o patrones de urls a incluir o excluir en el recuadro blanco poniendo una url por línea.
Por ejemplo, si quiero arrastrarme por Keyweo sólo las urls /fr/ aquí es lo que puedo poner en mi ventana de inclusión:
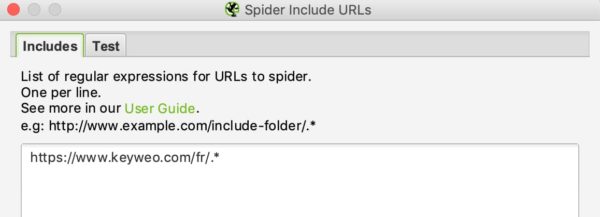
En cuanto a la reescritura de la url, podrá ver si su inclusión funciona probando una url que no debería estar integrada en el crawl:
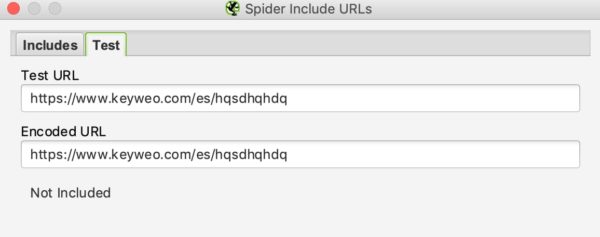
En nuestro ejemplo anterior podemos ver que el include funciona ya que las urls que contienen /es/ no se tienen en cuenta.
En caso de querer excluir ciertas urls, el proceso será similar.
5. Velocidad
En esta parte puede elegir qué tan rápido quiere que Screaming Frog rastree el sitio que quiere analizar. Esto puede ser útil cuando se quiere volver a analizar grandes sitios. Dejando la configuración por defecto podría llevar mucho tiempo rastrear este sitio web. Aumentar Screaming Frog de Maxthreads será capaz de arrastrarse por el sitio mucho más rápido.
Esta configuración debe utilizarse con precaución, ya que puede aumentar el número de solicitudes HTTP realizadas a un sitio, lo que podría ralentizarlo. En casos extremos también puede causar que el servidor se caiga o puede ser bloqueado por el servidor.
En general, recomendamos dejar esta configuración entre 2 y 5 threads máximos.
También ten en cuenta que puedes establecer un número de urls que se rastreen por segundo.
No dude en contactar con los equipos técnicos que gestionan el sitio para gestionar el rastreo lo mejor posible y evitar la sobrecarga del sitio.
6. Configuración del agente de usuario
En esta parte puede definir con qué agente de usuario quiere rastrear el sitio web. De forma predeterminada será Screaming Frog pero puede, por ejemplo, rastrear el sitio web como Google Bot (Desktop) o Bing Bot.
Esto podría ser útil, por ejemplo, en caso de que no se pueda rastrear el sitio porque este puede bloquear los rastreos con Screaming Frog.
7. Búsqueda y extracción personalizada
BÚSQUEDA PERSONALIZADA
Si quiere hacer análisis específicos resaltando las páginas que contienen ciertos elementos en su código HTML, le gustará la Búsqueda Personalizada.
Ejemplos de uso:
Quiere resaltar todas las páginas que contienen su código UA – Google Analytics. Podría ser inteligente hacer una búsqueda a gritos poniendo su código UA en la ventana de búsqueda. Esto podría utilizarse, por ejemplo, para ver si algunas de sus páginas no tienen instalado el código de análisis.
Usted es un blog sobre el tema del nacimiento y quiere ver en qué páginas aparece la palabra «box bebe» y luego optimizar las páginas que la contienen o al contrario las que no la contienen para posicionarse mejor en esta petición. Sólo tiene que poner en su ventana de búsqueda personalizada que contiene: «box bebe».
Verá en su búsqueda personalizada de Screaming Frog esto:
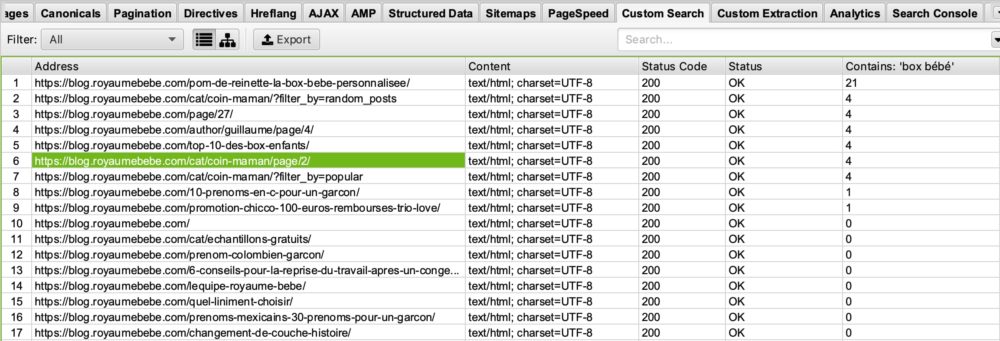
Si mira en la columna «Contains box Bébé» verá que la Screaming Frog ha enumerado las páginas que contienen «box bébé». Le dejaré imaginar para qué pueda usarlo más tarde en sus optimizaciones SEO.
EXTRACCIÓN
Screaming frog a través de su función de Extracción también puede permitirle rastrear ciertos datos para usarlos en su análisis posterior. Por ejemplo, utilizamos cada vez más esta herramienta en la agencia para algunos análisis específicos.
Para codificar estos datos sólo tiene que configurar su extractor diciéndole lo que debe recuperar a través de un Xpath, un CSSpath o un regex.
Encontrará toda la información sobre esta configuración en este artículo: https://www.screamingfrog.co.uk/web-scraping/
Ejemplos de usos:
Quiere recuperar la fecha de publicación de un artículo y luego decidir limpiar o reoptimizar ciertos artículos. Esta característica le permitirá recuperar esta información en su lista de resultados de Screaming Frog y luego, por ejemplo, exportarlos en Excel. Genial, ¿no?
Quiere exportar la lista de los productos de sus competidores que están en sus páginas de listas y que están en h2. Una vez más, puede configurar su extractor para recuperar esta información y luego jugar con estos datos en Excel.
Las posibilidades de usar esta característica de extracción son realmente ilimitadas. Depende de usted ser creativo y dominarlo perfectamente.
8. Acceso API
En esta ventana puede configurar la alimentación de datos de otras herramientas mediante la configuración de sus accesos API. Por ejemplo, puede subir fácilmente sus datos a Google Analytics, la Search Console de Google, Majestic SEO o ahrefs en sus tablas con la información de cada Url. Esto multiplicará el poder de su análisis y auditoría.
El único inconveniente es que hay que tener cuidado con los créditos de la API de las diferentes herramientas.
9. Autenticación
Algunos sitios requieren un nombre de usuario y una contraseña para acceder a todo el contenido. Screaming Frog le permite manejar los diferentes casos de acceso a través de una contraseña y un login.
CASOS BÁSICOS DE AUTENTICACIÓN
En la mayoría de los casos no tendrá nada que configurar ya que por defecto si Screaming Frog se encuentra con una ventana de autenticación le pedirá un nombre de usuario y una contraseña para poder realizar el rastreo.
Aquí está la ventana que debería tener:
Sólo tienes que introducir el nombre de usuario y la contraseña y Screaming Frog podrá arrastrarse.
En algunos casos puede haber un bloqueo a través del robots.txt. Tendrá que referirse al punto 2/ que hemos visto para ignorar el archivo robots.txt.
CASO DE UN FORMULARIO DE SITIO INTERNO
En el caso de un formulario interno, puede simplemente rellenar sus accesos en la parte basada en la autenticación > formulario y luego permitir que el crawler acceda a las páginas que desea analizar.
10. Sistema
ALMACENAMIENTO
Esta característica también es importante de dominar en caso de que necesite rastrear sitios con más de 500.000 URL.
Tiene dos opciones en esta ventana: Almacenamiento de memoria y almacenamiento de base de datos.
Por defecto, Screaming Frog utilizará el almacenamiento de memoria, que es como utilizar la RAM de su ordenador para rastrear el sitio. Esto funciona muy bien para los sitios que no son demasiado grandes. Sin embargo, rápidamente alcanzará los límites para los sitios de más de 500.000 Urls. Su herramienta puede frenar mucho y el rastreo durará un tiempo relativamente largo.
En el otro caso, le recomendamos que cambie a Almacenamiento de la base de datos, especialmente si tiene un disco SSD. La otra ventaja del almacenamiento de la base de datos es que sus rastreos pueden ser respaldados y recuperados fácilmente desde la interfaz Screaming Frog. Incluso si el rastreo se detiene, puede reanudarlo. Esto realmente puede ahorrarle, en algunos casos, largas horas de arrastre.
MEMORIA
Aquí es donde definirá la memoria que Screaming Frog puede usar para trabajar. Cuanto más aumente la memoria, más Screaming Frog podrá arrastrarse por un gran número de Urls. Especialmente si está configurado como almacenamiento de memoria.
11. El modo de rastreo
SPIDER
Este modo es la configuración básica de Screaming Frog. Una vez que ingrese su URL, Screaming Frog seguirá los enlaces de su sitio para navegarlo por completo.
MODO DE LISTA
Este modo es muy útil porque le permite decirle a Screaming Frog que navegue por una lista específica de Urls.
Por ejemplo, si quiere comprobar el estado de una lista de urls que tiene, puede simplemente subir un archivo o copiar y pegar su lista de Urls manualmente.
MODO SPIDER
Este modo no implica el rastreo. Le permite subir un archivo con, por ejemplo, sus títulos y meta descripciones para ver cómo se vería en términos de optimización SEO. Puede utilizarse, por ejemplo, para comprobar la longitud de los títulos y la meta descripción después de las modificaciones en Excel, por ejemplo.
Analice sus datos de rastreo
La interfaz de Screaming Frog:
Antes de analizar los datos que nos presenta Screaming Frog, es importante entender cómo está estructurada la interfaz.
Normalmente tendrá algo así:
Cada parte tiene su propio uso y le permitirá no perderse en todos los datos disponibles:
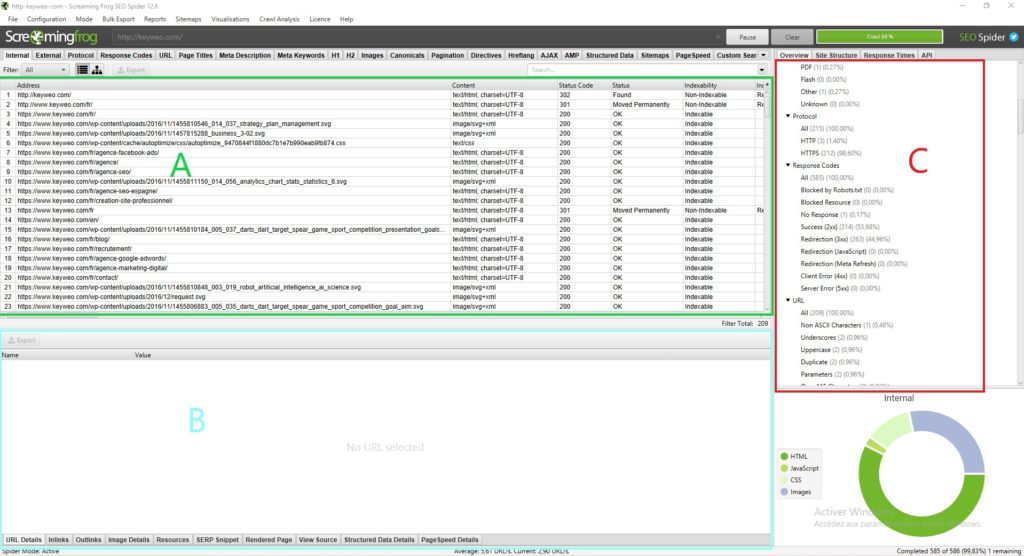
Parte A (en verde): Esta parte corresponde a la lista de recursos rastreados con para cada columna indicaciones de SEO que son específicas para cada línea. En general, aquí es donde encontrará la lista de sus páginas y la información específica de cada página como el código de estado, la indexación de la página, el número de palabras… Esta vista cambiará dependiendo de lo que seleccione en la parte C.
Parte B (en azul): Es en esta parte donde podrá tener una visión más detallada de cada recurso que esté analizando haciendo clic en él. Por ejemplo, se puede tener una vista previa de una página de sus enlaces, las imágenes presentes y mucha otra información que puede ser muy útil.
Parte C (en rojo): Esta parte será importante de observar para llevar a cabo su análisis, porque aquí es donde podrá ver punto por punto lo que puede ser optimizado, y Screaming Frog también le dará alguna ayuda para facilitar su análisis. Ejemplo: Falta de metadatos, múltiples H1s…
Para orientarse en el análisis de sus datos le recomendamos que pase por la parte C.
Overview (Parte C):
1. El resumen
En esta parte se puede tener una visión global del sitio incluyendo el número de urls del sitio (imágenes, html…), el número de urls externas e internas bloqueadas por el robots.txt, el número de urls que el crawler pudo encontrar (internas y externas).
De este modo, tendrá una valiosa información sobre el sitio en un solo vistazo.
2. Elementos SEO : Interno
Encontrará en esta parte todas las urls internas de su sitio.
HTML
Normalmente es muy interesante mirar el número de Urls HTML. Podría, por ejemplo, comparar el número de urls con el número de páginas indexadas en Google con el comando site: . Esto podría darle información valiosa si muchas páginas no están indexadas en Google.
Al hacer clic en HTML verá que su lado izquierdo contendrá mucha información para analizar, cómo:
=> Código de estado de la página
=> Indexabilidad
=> Información sobre los títulos (contenido, tamaño)
=> Información de la meta descripción (contenido, tamaño)
=> Meta Palabra clave: no necesariamente muy útil para mirar a menos que todavía se utilicen por el sitio en cuestión. Podrías, por ejemplo, limpiar estas etiquetas
=> H1 (El contenido, el tamaño, la presencia de un segundo h1 y su tamaño)
=> H2 (El contenido, el tamaño, la presencia de un segundo h2 y su tamaño)
=> Meta Robots
=> Etiqueta de los robots X
=> Meta refresh
=> La presencia de un canónico
=> La presencia de una etiqueta rel next o rel prev
=> El tamaño de la página
=> El número de palabras en la página
=> La proporción del texto: proporción entre el texto y el código
=> Profundidad de rastreo: La profundidad de la página en cuestión en el sitio. La casa estará en el nivel 0 si empiezas el rastreo con esta página. Un clic en la página 1 lejos de la casa será en la profundidad 1 y así sucesivamente. Sabiendo que es generalmente interesante reducir esta profundidad en su sitio
=> Inlinks / inlinks únicos: número de enlaces internos que apuntan a la página en cuestión
=> Outlinks / Unique outlinks : número de enlaces que salen de esta página
=> Tiempo de respuesta: tiempo de respuesta de la página
=> URL de redireccionamiento: página a la que se redirige la página si hay un redireccionamiento
También podrá encontrar todos estos elementos navegando por los diferentes elementos de la columna derecha.
Si conecta la api Google Search Console, Google Analytics, Ahrefs… también tendrá disponibles otras columnas que serán muy interesantes de analizar.
JAVASCRIPT, IMÁGENES, CSS, PDF…
Haciendo clic en cada parte podrá tener información sobre cada tipo de recurso en su sitio.
3. Elementos SEO: Externos
La parte externa corresponde a todas las Urls que se dirigen al exterior de su sitio. Por ejemplo, aquí es donde puede encontrar todos los enlaces externos que son creados.
Podría ser interesante, por ejemplo, analizar las urls salientes de su sitio y ver su estado. Si tienes 404, puede ser una buena idea corregir su enlace o eliminarlo para evitar referirse a páginas rotas.
4. Protocolo
En esta parte será capaz de identificar HTTP y HTTPS Urls.
Si tiene muchas urls HTTP o páginas duplicadas en http y https sería útil gestionar la redirección de sus páginas HTTP a su versión HTTPS.
Otro punto, si tiene urls HTTP que apuntan a otros sitios podría comprobar si la versión HTTP de estos sitios no existe y reemplazar los enlaces.
5. Código de respuesta
La sección códigos de respuesta agrupa sus páginas por tipo de código.
=> No hay respuesta: Esto generalmente corresponde a las páginas que Screaming Frog no pudo arrastrar.
=> Éxito: Deberías tener todas tus páginas aquí en el estado 200. Es decir que son accesibles
=> Redirección: Deberá tener en esta parte todas las páginas en estado 300 (301, 302, 307…) . Podría ser interesante ver cómo reducir este número para enviar a Google directamente a las páginas en estado 200.
=> Páginas de error: Aquí obtendrá todas las páginas de error con, por ejemplo, un estado 404. Será importante mirar la causa y hacer una 301.
=> Error del servidor: Todas las páginas que informan de un error del servidor.
6. URL
En esta sección encontrará la lista de sus url y los posibles problemas o mejoras asociadas a ellas.
Puedes por ejemplo ver tus urls con mayúsculas o tus urls duplicadas.
7. Títulos de las páginas
Tendrá aquí mucha información sobre sus títulos y podrá optimizarlos para hacerlos mucho más amigables con el SEO.
Aquí está la información que puedes encontrar:
=> Desaparecido: Esto corresponderá a sus páginas que no tienen título. Así que tendrá que asegurarse de añadirlas si es posible.
=> Duplicado: Aquí tendrá todos los títulos duplicados de su sitio. Lo ideal es evitar tenerlos. Así que depende de usted ver cómo optimizarlos para evitar esta duplicación.
=> Más de 60 caracteres: A partir de un cierto número de caracteres, los títulos se recortan en los resultados de Google. Así que asegúrese de que sean unos 60 caracteres para evitar problemas.
=> Por debajo de 30 caracteres: Aquí encontrará los títulos que podrá optimizar en términos de tamaño. Añadir unas pocas palabras estratégicas más cercanas a los 60 caracteres podría ayudar a optimizarlas.
=> Más de 545 Píxeles / Menos de 200 Píxeles: Un poco como los elementos anteriores esto te da un indicador de la longitud de sus títulos pero esta vez en píxeles. La diferencia es que puede optimizar sus títulos usando letras con más o menos píxeles para maximizar el espacio.
=> Igual que H1: Esto significa que su título es idéntico a su h1.
=> Múltiples: Si tiene páginas con múltiples títulos, aquí es donde puede identificar este problema y ver las páginas a corregir.
8. Meta Descripción
En el mismo modelo que los títulos tendrá en esta sección muchas indicaciones para optimizar su meta descripción según su tamaño, su presencia o el hecho de que estén duplicados.
9. Meta Keywords
No es necesariamente útil tener esto en cuenta, a menos que las páginas parecen tener mucho para des optimizarlas.
10. H1 & H2
Vous pourrez dans ces parties voir s’il y a des optimisations à mener sur vos balises Hn
Par exemple si vous avez plusieurs h1 dans une même page il pourrait éventuellement être intéressant de réfléchir à n’en garder qu’un si ça fait sens. Ou si vous avez des h1 dupliqués entre vos pages, vous pourriez faire en sorte de les retravailler
11. Imágenes
Se pueden encontrar optimizaciones para ser llevadas a cabo en sus imágenes como por ejemplo la optimizacion de sus imágenes de más de 100kb o añadir Alt en las imágenes que no tienen ninguna.
12. Canonical
Un canónical se usa para indicar a Google que debe ir a esta o aquella página porque es el original. Por ejemplo, tiene una página con parámetros y esta página tiene un contenido duplicado de su página sin parámetros. Podría poner una canónical en la página con parámetros para decirle a Google que la página sin parámetros es la principal y que más bien debería tener en cuenta la página original.
En esta parte de Screaming Frog tendrá toda la información sobre la gestión de las canónicals en su sitio.
13. Paginación
Aquí tendrá toda la información relativa a la paginación en su sitio para que pueda manejarla lo mejor posible.
14. Directrices
La sección de directicres muestra la información contenida en la etiqueta de los meta robots y en la etiqueta de los X-Robots. Podrá ver las páginas sin índice, las páginas sin seguimiento, etc.
15. Hreflang
Cuando se audita un sitio en varios idiomas es muy importante ver si el sitio tiene etiquetas hreflang para ayudar a google a entender qué idioma se utiliza en el sitio, incluso si podemos asumir que es cada vez más capaz de entenderlo por sí mismo.
16. AMP
Sus páginas de AMP terminarán aquí y podrá identificar los problemas de SEO asociados.
17. Datos estructurados:
Para tener información en esta parte debe activar primero en su configuración de spider los elementos específicos de los datos estructurados: JSON-LD, Microdatos, RDFa
Entonces tendrá mucha información para optimizar su implementación de datos estructurados en el sitio.
18. Sitemaps
En esta parte podrá ver las diferencias entre lo que tiene en su sitio y en su mapa del sitio.
Por ejemplo, es una buena manera de identificar sus páginas huérfanas.
Para tener datos en esta parte también debe activar la posibilidad de rastrear su Sitemap en la configuración del crawler y para simplificar la cosa añade el enlace a su Sitemap directamente en la configuración.
19. Pagespeed
Mediante el uso de la API de información sobre la velocidad de la página puede identificar y solucionar fácilmente los problemas de velocidad de la página analizando los datos de esta pestaña.
20. Búsqueda y recuperación personalizada
Si desea desechar elementos o hacer búsquedas específicas en el código de una página, aquí es donde podrá recuperar los datos.
21. Analytics y Search Console
Conectando también Screaming Frog a la API de la Search Console puedes encontrar mucha información útil en estas pestañas.
Por ejemplo, también encontrará aquí páginas huérfanas presentes en sus herramientas pero no en el rastreo o páginas con una tasa de rebote superior al 70%.
22. Link Metrics
Conecta a Screaming Frog con las Apis Ahrefs y Majestic y destaca en esta parte la información sobre el netlinking de tus páginas (ejemplo: Trust flow, Citacion flow…).
Las características adicionales de Screaming Frog
Analizando la profundidad de un sitio
Si quiere ver la profundidad de su sitio puede mirar la pestaña Estructura del sitio en la parte derecha junto a Visión general:
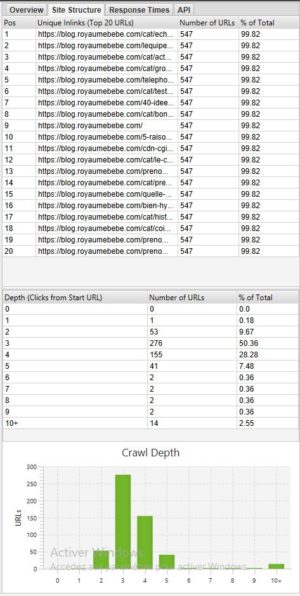
En general es preferible tener un sitio con la mayoría de las páginas accesibles en 3 – 4 clics. En nuestro ejemplo anterior, por ejemplo, sería necesario optimizar la profundidad porque hay páginas con + de 10 de profundidad.
Visión espacial de su sitio
Una vez terminado el rastreo, a veces es interesante ir a Visualizaciones> Diagrama de rastreo dirigido forzado para tener una visión global de su sitio en forma de nodo.
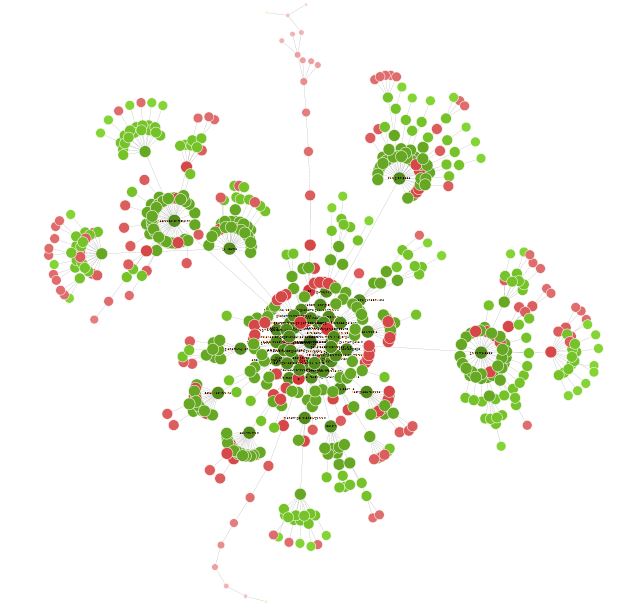
Todos los pequeños puntos rojos, por ejemplo, pueden ser analizados para entender si hay un problema o no.
Esta visión también puede llevarle a cabo una reflexión sobre la organización de su sitio y su red interna.
Pasando un poco de tiempo con esta visualización se pueden encontrar muchas formas interesantes de optimización.
Conclusión Screaming Frog
Screaming Frog será, por lo tanto, una herramienta esencial para cualquier buen SEO. La herramienta, si la dominas, permite hacer muchas cosas, desde el análisis técnico de SEO hasta el «site scraping».